
Tous droits réservés pour tous pays. All rights reserved.
| Serveur © IRCAM - CENTRE POMPIDOU 1996-2005. Tous droits réservés pour tous pays. All rights reserved. |
Journal of the Acoustical Society of America, 97, 3736-3748 (1995)
Copyright © ASA 1995
 F0) is usually attributed to
mecanisms that exploit harmonic structure. To decide whether identification is
aided primarily by the harmonic structure of the target ("harmonic
enhancement") or that of the ground ("harmonic cancellation"), pairs of
synthetic vowels, each of which was either harmonic or inharmonic, were
presented to listeners for identification. Responses for each vowel were
scored according to the vowel's harmonicity, the harmonicity of the vowel that
accompanied it, and F0. For a given target, identification was better
by about 3% for a harmonic ground unless the target was also harmonic with the
same F0. This supports the cancellation hypothesis. Identification was worse
for harmonic than for inharmonic targets by 3-8%. This does not support the
enhancement hypothesis. When both vowels were harmonic, identification was
better by about 6% when the F0s differed by 1/2 semitone. However, when at
least one vowel was inharmonic, F0 had no significant effect.
Identification of constituents of pairs was generally not the same when the
target was harmonic and the ground inharmonic or vice-versa. Results are
interpreted in terms of harmonic enhancement and harmonic cancellation, and
alternative explanations such as phase effects are considered.
F0) is usually attributed to
mecanisms that exploit harmonic structure. To decide whether identification is
aided primarily by the harmonic structure of the target ("harmonic
enhancement") or that of the ground ("harmonic cancellation"), pairs of
synthetic vowels, each of which was either harmonic or inharmonic, were
presented to listeners for identification. Responses for each vowel were
scored according to the vowel's harmonicity, the harmonicity of the vowel that
accompanied it, and F0. For a given target, identification was better
by about 3% for a harmonic ground unless the target was also harmonic with the
same F0. This supports the cancellation hypothesis. Identification was worse
for harmonic than for inharmonic targets by 3-8%. This does not support the
enhancement hypothesis. When both vowels were harmonic, identification was
better by about 6% when the F0s differed by 1/2 semitone. However, when at
least one vowel was inharmonic, F0 had no significant effect.
Identification of constituents of pairs was generally not the same when the
target was harmonic and the ground inharmonic or vice-versa. Results are
interpreted in terms of harmonic enhancement and harmonic cancellation, and
alternative explanations such as phase effects are considered.
Each strategy has its advantages and disadvantages. Harmonic enhancement allows harmonic sounds such as voiced speech to emerge from any type of interference (except harmonic interference with the same F0 as the target). Harmonic cancellation on the other hand allows any type of target to emerge from harmonic interference. Enhancement works best when the signal-to-noise ratio is high, because the F0 of the target is then relatively easy to estimate. However separation is probably most needed when the signal-to-noise ratio is low, in which case cancellation should be easier to implement. Cancellation removes all components that belong to the harmonic series of the interference, and may thus distort the spectrum of the target. Enhancement should cause no spectral distortion to the target, as long as it is perfectly harmonic. Cancellation of perfectly harmonic interference can be obtained using a filter with a short impulse response, whereas enhancement requires a filter with a long impulse response to be effective (de Cheveigné 1993a). The non-stationarity of speech may limit the effectiveness of such filters.
The aim of this paper is to study the degree to which each strategy is used by the auditory system in a double vowel identification experiment. An answer to this question may allow us to better understand auditory processes of sound organization, and refine our models of harmonic sound separation. We first review the literature on mixed vowel identification experiments and present the rationale and predictions for our experiment. We then present our experimental design and methods, report the results, and analyze them in relation to the predictions.
Another cue that might be expected to reinforce F0 differences is frequency modulation, particularly if competing streams are modulated incoherently. McAdams (1989) and Marin and McAdams (1991) demonstrated that frequency modulation increased the perceptual prominence of a vowel presented concurrently with two other vowels at relatively large F0 separations (5 semitones, or 33%). However, they also found that this increase was independent on whether the vowels were modulated coherently or not. Subsequent studies confirmed that the effects of frequency modulation incoherence can be accounted for by the instantaneous differences in F0 that it causes (Demany and Semal 1990; Carlyon 1991; Summerfield 1992; Summerfield and Culling 1992)
These results all suggest a crucial importance of harmonicity, exploited by the
auditory system when there are differences in fundamental frequency
(F0) between constituents of an acoustic mixture. The effects of
F0 have been studied in detail by a number of authors (Assmann and
Summerfield, 1989, 1990; Scheffers, 1983; Summerfield and Assmann, 1991;
Zwicker 1984; Chalikia & Bregman, 1989, 1993; Darwin and Culling, 1990;
Culling and Darwin, 1993a). In these studies, two synthetic vowels were
presented simultaneously at various F0 values and subjects were
requested to identify both vowels from a predetermined set of five to eight
vowels. Identification scores reflecting the ability to identify both vowels
(combinations-correct score) for several of these studies are plotted in Figure
1.
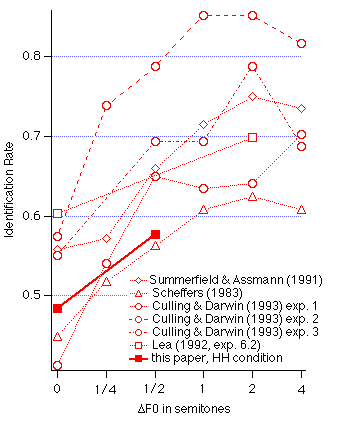
Fig. 1 Dotted lines: combination-correct identification rates as a function of F0 reported in previous studies. Continuous line: combination correctrates obtained in this study for mixtures of harmonic vowels (HH condition).
There are large differences in overall identification rate between studies
that may be attributed to differences in training of subjects, presence or
absence of feedback, size of vowel set, inclusion of pairs of identical vowels,
stimulus duration, level, etc.. A common trend is a rapid increase in
identification performance with F0 up to between 1/2 and 2 semitone
separation (3-12% difference in F0), followed by an asymptote. This effect is
usually explained by assuming that the mechanism that exploits the harmonic
structure of the vowel spectrum is effective when the F0s are different but
fails when they are the same and the harmonic series of both vowels coincide.
However, a question that none of these studies has addressed is whether it is
primarily the harmonicity of the vowel being recognized that aids its
segregation and subsequent identification, or that of the background vowel.
This leaves dangling many issues involved in the design of voice separation
models. The primary aim of the present study is to directly test the effect of
the harmonicity of both the target vowel and the background vowel on the
target's identification.
One study that approached this question was conducted by Lea (1992; Lea and Summerfield 1992). He presented listeners with pairs of vowels of which each could be either voiced or whispered, and requested them to identify both vowels. He scored results according to the harmonicity of the vowel being answered (the target) and that of the other vowel (the ground). He found that targets were better identified when the ground was voiced than when it was whispered. There was no significant advantage when the target itself was voiced rather than whispered. However with a slightly different method, Lea and Tsuzaki (1993a,b) found that targets were better recognized when they were voiced.
A difficulty with this experiment is that it requires voiced and whispered vowels to be equivalent in both "phonetic quality" and "masking power" (except insofar as these depend on harmonicity). This is a difficult requirement because it is not evident how one should go about matching the continuous spectrum of a whispered vowel to the discrete spectrum of a voiced vowel. Lea (1992) used a model of basilar membrane excitation to match the vowels, but the possibility remains that some imbalance, for example of level, might have affected the results. Here we describe a similar experiment in which whispered vowels are replaced by inharmonic vowels with spectral structure and density closer to those of harmonic vowels.
F0) in order to compare their effects and study their interaction, as well
as to allow comparisons with previous studies. Pairs of vowels were presented
simultaneously. Subjects were asked to identify both vowels and respond with an
unordered pair of vowel names. For each vowel in the stimulus, the answer was
deemed correct if the vowel's name appeared within the response pair. This
answer was classified according to the harmonic state of that vowel (the
target), the state of the other vowel (the ground), and the nominal F0
difference between them. This step was repeated for the second vowel in the
pair, reversing the roles of target and ground.
In this paper, the notation 'HI', for example, indicates a harmonic target with
an inharmonic ground, and 'R(HI)' indicates the identification rate for that
target. Other combinations are noted IH, HH, and II. Where necessary, the
relation between the F0s may also be specified: HI0 signifies the same F0 and
HIx signifies a different F0 (HI implies that both F0 conditions are
taken together). For each hypothesis concerning the strategy that is used by
the auditory system to separate harmonic sounds, specific predictions can be
made concerning the outcome of this experiment.
R(HI0) > R(II0),
R(HIx) > R(IIx),
R(HHx) > R(IHx).
If the hypothesis is false, these differences should be insignificant.
R(IH0) > R(II0),
R(IHx) > R(IIx),
R(HHx) > R(HIx).
If the hypothesis is false, the differences should be insignificant. In addition to these two hypotheses that our experiment was specifically designed to test, there are others that are worth considering.
R(IH0) = R(HI0),
R(IHx) = R(HIx).
Specific cues or mechanisms that might show that behavior are:
R(all conditions other than HH0) > R(HH0).
F0. Beating occurs for example if two partials belonging to different
vowels fall within the same auditory filter: the output fluctuates at a rate
that depends on the difference in frequency between the partials. Fluctuations
may allow the amplitudes of the two partials to be better estimated, as long as
they are neither too slow to be appreciable within the duration of the
stimulus, nor too fast to be resolved temporally by the auditory system.
Beating is likely to affect identification in a complex fashion, but insofar as
it depends on frequency difference between partials of both vowels, both should
be equally affected.
R(all conditions other than HH0, II0) > R(HH0,II0).
In contrast to the predictions of the component-mismatch hypothesis, the II0 condition does not promote segregation here (assuming that all of the inharmonic stimuli used are percieved as having a similar quality).
F0F0 effects are likely to be smaller when either vowel
is inharmonic than when both are harmonic. For example in the IH condition the
effectiveness of enhancement would be reduced, whereas that of cancellation
should change relatively little with F0 (much of the F0
effect in the HH condition is due to the fact that when F0=0 all
target components fall precisely on the ground vowel's harmonic series, and are
cancelled together with those of the ground). Component mismatch or beating
should also be less affected by F0 than in the HH condition, leading
to smaller effects when either vowel is inharmonic. On the other hand when
both vowels are harmonic, all models predict alike:R(HHx) > R(HH0).
It is or this reason that classic double-vowel experiments do not allow us to choose between hypotheses.
The F0 values we chose allow F0s of 0 and 2.9% (1/2 semitone) to be
investigated. Based on previous studies (Fig. 1), such values should ensure an
effect large enough to be significant while leaving room for improvement with
other factors. The range corresponds approximately to the maximum frequency
shift of the partials of our inharmonic vowels, and to the mistuning up to
which individual partials still make a full contribution to virtual pitch, as
estimated by Moore et al. (1985)
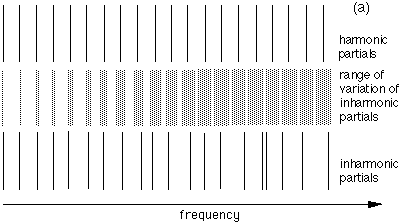
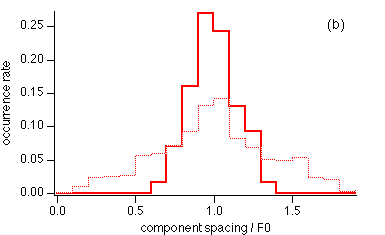
Fig. 2 (a) Top: harmonic series; middle: range of frequencies from which inharmonic partials are drawn; bottom: a particular inharmonic series. (b) Histogram showing the distribution of inter-component spacings (divided by F0) for inharmonic series. Full line: spacings between components up to 750 Hz (F1 region). Dotted line: spacings between components up to 3 kHz (F1-F3 region).
Subjects were informed that they would hear individual vowel sounds and were to identify them as one of /a/, /e/, /i/, /o/, /u/ by typing the appropriate key on the computer keyboard (a, e, i, o, u, respectively). They were informed that they needed to attain a criterion performance level of 95% to continue on to the main experiment. The computer logged the spectral envelope, F0, harmonicity and response to each stimulus in a separate file for each subject. Each combination of allophone, nominal F0, and harmonicity was presented once for a total of 300 trials that were presented in random order (Appendix 4).The pre-test lasted 15 minutes on average.
A multivariate repeated measures analysis of variance on factors vowel class (5) X harmonicity (2) X F0 (3) was performed with, as the dependent variable, proportion correct identifications across allophones by each subject within a given condition. Each data point was based on 10 judgments. The analysis revealed that the main effect of vowel noted above was significant (F(4,124)=3.5, p=0.016, GG=0.78). [1] There was no significant effect of fundamental frequency nor any significant interactions involving this factor. There was no main effect of harmonicity but the interaction between vowel and harmonicity was highly significant (F(4,124)=6.4, p=0.0002, GG=0.88) indicating an effect of harmonicity on vowel identification that is limited to certain vowels. Contrasts between harmonic and inharmonic versions for each vowel class showed that the effect of harmonicity was only significant for /e/ and /u/ vowels. Harmonic stimuli were better identified than inharmonic ones for /e/ by 2.8% (F(1,124)=19.5, p<0.0001, GG=0.88) and the reverse was true by 1.4% for /u/ (F(1,124)=4.5, p=0.041, GG=0.88). We can summarize these results by noting that there were small, though significant, effects of harmonicity for some stimuli and no effect of F0 for any stimuli. The general level of performance is quite good for the large majority of allophones in both harmonic and inharmonic versions.
F0 (2), were crossed
giving 80 different combinations.
In addition to the factors that interest us, the design contained others that
might also influence the phonetic quality of the target or the masking power of
the ground: absolute F0, choice of inharmonic pattern, choice of allophone, or
presentation order. To avoid any systematic bias due to these factors, the
following precautions were taken: a) Pairs were duplicated so that each vowel
of each pair occurred once at the higher and once at the lower F0 when
F0!=0. b) For each inharmonic allophone, the same component pattern
was used to synthesize different F0 conditions. c) Allophones were assigned in
a balanced fashion across conditions. For example the subset of allophones
representing the eight repetions of the vowel /a/ (2 positions X 4 other
vowels) in the HH0 condition within a presentation of the stimulus set also
represented that vowel in all other main conditions (HHx, HI0, etc.). Other
subsets were used for other presentations. d) Stimuli were presented in random
order, and this order was renewed for each run and each subject.
In the inharmonic state each allophone used a different component pattern.
Since vowels within a pair were different, component patterns within an
inharmonic-inharmonic pair were also different. As noted above, the same
subsets of allophones appeared in all conditions, but for practical reasons it
was not possible to guarantee that the occurence of allophone pairs was
similarly balanced. Allophones were paired at random, and the pairing was
renewed for each presentation and subject. Duplication of F0
conditions resulted in a 160-stimulus set.
Preliminary experiments had shown that when vowels are mixed at equal rms signal levels, one vowel might dominate the pair due to unequal mutual interference, as noted by McKeown (1992). In that case, the identification probability of one vowel is likely to be at its "floor" and the other at its "ceiling", both being thereby insensitive to the conditions of interest. To avoid such a situation, we performed a preliminary experiment to determine levels of equal "mutual interference" (see Appendix A-3). From these results we derived a level correction factor for all pairs, such that identification rates for both vowels were the same. Vowel levels were adjusted according to this factor, the vowels were summed, and the rms signal level of the sum was set to a standard level for all pairs.
F0 in randomized order for a
total of 480 stimuli. Responses for each subject were gathered in a file. Each response was scored twice, once for each vowel present within the stimulus. The vowel was deemed correctly identified if its name appeared within the response pair. This partial response was classified according to the harmonic state of that vowel (the target), the state of the other vowel (the ground), the nominal F0 difference between them, and the names of both vowels. This procedure was repeated for the other constituent vowel, reversing the roles of target and ground, leading to a total of 960 "answers" for each subject. Figure 3 summarizes these conditions and their notation. This method of scoring is equivalent to that used by Lea (1992) to obtain "constituents-correct" scores.
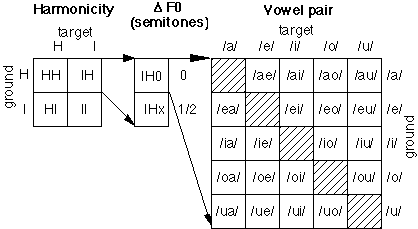
Fig. 3 Response conditions: Target harmonicity X Ground harmonicity X
F0 X vowel pairs.
F0 condition, proportion correct
identification measures for each target vowel were calculated for each subject
across all vowel combinations, yielding eight data points per subject. Each
data point was based on 120 judgments (20 vowel pairs X 2 vowel identifications
X 3 repetitions). A multivariate repeated measures analysis of variance was
performed on factors F0 (2), target harmonicity (2), and ground
harmonicity (2). All main effects and interactions were statistically
significant (see Table I). Subsequent discussion will focus on tests of the
various hypotheses outlined in the introduction.
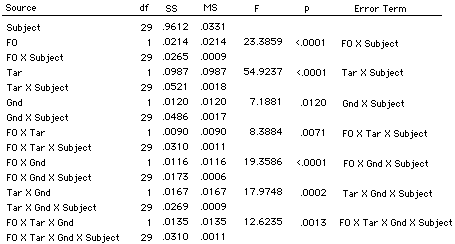
Table I Analysis of variance table for the main experiment. Dependent variable: Mean Identification performance for target vowels across vowel pairs. Independent variables: fundamental frequency difference (F0), target harmonicity (Tar), ground harmonicity (Gnd).
F0F0.
Each line represents one of the four combinations of target and ground
harmonicity. Filled symbols represent harmonic targets and open symbols
inharmonic targets. Squares represent harmonic grounds and circles inharmonic
grounds. When both vowels are harmonic, performance increases with F0
by about 6%. Planned contrasts show that this effect is highly significant
(F(1,29)=50, p<0.0001). When at least one vowel is inharmonic the effect is
not significant (for HI: F(1,29)=0.1; for IH: F(1,29)=0.4; for II:
F(1,29)=0.4). We take advantage of this fact to group these conditions across
F0 in subsequent contrasts.
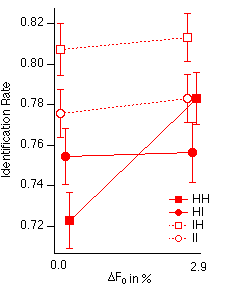
Fig. 4 Identification rate as a function of F0 for each of the harmonicity conditions. Error bars represent ± 1 standard error of the mean. The standard deviations vary between 0.066 and 0.081. Data points for HH and HI are displaced horizontally for visibility.
F0=0 (IH
vs. II: F(1,29)=26, p<0.0001; HHx vs. HI: F(1,29)=14, p=0.0008). The
improvement in identification rate is about 3%. These results are compatible
with the cancellation hypothesis. An additional contrast shows that when the
target is harmonic and F0=0, performance is significantly worse with a
harmonic ground, also by about 3% (HH0 vs. HI0: F(1,29)=13, p=0.0009).
F0 and whatever the nature of the ground, identification
is worse when the target is harmonic. Contrasts planned to test the enhancement
hypothesis (Introduction, B.2) are highly significant (HI vs. II: F(1,29)=15,
p=0.0004; HHx vs. IH: F(1,29)=13, p=0.0008), but the direction of the effects
observed is opposite to that predicted by that hypothesis. The effect
is similar in size, about 3%, to what was observed for ground harmonicity. An
additional contrast shows that the larger effect (about 8%) obtained when the
ground is harmonic and F0=0 is also significant (HH0 vs. IH0:
F(1,29)=99, p<0.0001).
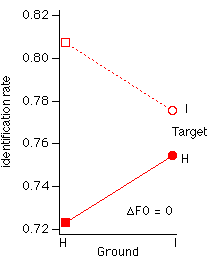
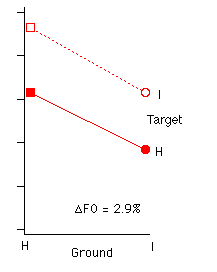
Fig. 5 Identification rate of target as a function of ground harmonicity, for harmonic and inharmonic targets and nominal F0 differences of 0 and 1/2 semitone.
Performance for HH0 is worse than for all other conditions (HI vs. HH0: F(1,29)=19, p<0.0001; IH vs. HH0: F(1,29)=142, p<0.0001; II vs. HH0: F(1,29)=59, p<0.0001). This would be consistent with the component-mismatch hypothesis, were it not for the asymmetry between HI and IH mentioned above.
Performance is better for IH than for II (F(1,29)=26, p<0.0001) but worse for HI than for II (F(1,29)=15, p=0.0004). This is inconsistent with the quality differences hypothesis, already weakened by the asymmetry between HI and IH.
| Response: | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ae | ai | ao | au | ei | eo | eu | io | iu | ou | |
| Stimulus | ||||||||||
| ae | 1182 | 81 | 41 | 18 | 55 | 45 | 13 | 1 | 1 | 3 |
| ai | 169 | 1114 | 21 | 42 | 53 | 3 | 9 | 11 | 10 | 8 |
| ao | 29 | 2 | 953 | 24 | 0 | 236 | 3 | 78 | 2 | 113 |
| au | 3 | 3 | 28 | 434 | 5 | 26 | 209 | 19 | 149 | 564 |
| ei | 172 | 47 | 1 | 1 | 957 | 82 | 111 | 22 | 47 | 0 |
| eo | 139 | 6 | 134 | 8 | 48 | 906 | 37 | 82 | 3 | 77 |
| eu | 31 | 44 | 13 | 76 | 148 | 140 | 371 | 102 | 297 | 218 |
| io | 29 | 73 | 46 | 13 | 130 | 262 | 51 | 707 | 66 | 63 |
| iu | 3 | 66 | 9 | 103 | 59 | 22 | 172 | 182 | 494 | 330 |
| ou | 2 | 3 | 26 | 298 | 2 | 32 | 234 | 20 | 160 | 663 |
| total | 1759 | 1439 | 1272 | 1017 | 1457 | 1754 | 1210 | 1224 | 1229 | 2039 |
| % | 12.2 | 9.9 | 8.8 | 7.1 | 10.1 | 12.2 | 8.4 | 8.5 | 8.5 | 14.2 |
Table II Confusion matrix for vowel pairs (response orders are confounded). The total number of times each stimulus type was actually presented was 1440. The bottom two rows give the total number of responses of each kind, and the proportion of total responses they represent.
F0. It is nevertheless of
interest to note such effects. Figure 6 displays the identification rate as a
function of ground harmonicity for each of the 20 vowel pairs, for both
conditions of F0 and both conditions of target harmonicity. Vowel
pairs differ considerably in overall identification rate, as well as in the
size and direction of the effects of ground harmonicity. These differences
might be due to genuine vowel specificities, or to some effect of the level
correction factors that we applied, or possibly to differences between the
component patterns used to synthesize each vowel pair (each allophone had its
own inharmonic pattern when it was synthesized in an inharmonic state; each
vowel was thus represented by a different set of patterns). Our experimental
design does not allow us to decide which of these factors are responsible for
the differences. It is however of interest to keep them in mind when
interpreting our main effects. For example it may be that the population of
"inharmonic" patterns that we treat as homogenous is actually made up of
members with widely differing properties.
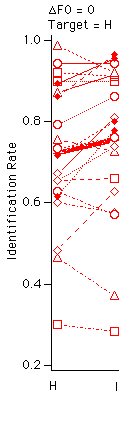


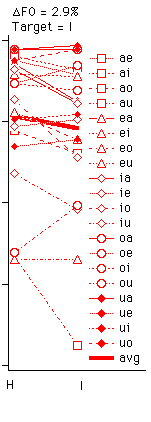
Fig. 6 Identification rate of target vowel as a function of ground harmonicity for each vowel pair and for all four conditions of F0 and target harmonicity. The thick lines without markers represent the effect averaged over vowel pairs, also plotted in Fig. 5.
F0 in Comparison with Previous StudiesF0 is quite similar.
Although our task was relatively easy (chance level is 10%, as in Culling and
Darwin (1993a) and Lea (1992), compared to 3.8% for Scheffers (1983), or 6.7%
for Summerfield and Assmann (1991)), our rates are relatively low. This
probably reflects the greater variability of our stimulus material, and
differences in training (we used a large number of relatively untrained
subjects).
F0 of a 1/2-semitone, whatever the target, and at F0=0
when the target is inharmonic, identification is better when the ground is
harmonic. This is consistent with the cancellation hypothesis. No advantage
was to be expected for a harmonic ground in the fourth condition (F0=0
with a harmonic target), but identification was actually worse when the
ground was harmonic than when it was inharmonic (an unexpected outcome). One
possible explanation is that our inharmonic stimuli were approximately harmonic
with a "pseudo period" that differed from their nominal period (on informal
listening they often appeared to have a pitch different from that of a harmonic
vowel of same nominal F0). A harmonic sieve tuned to reject the "peudo-period"
might partially remove the inharmonic ground without completely removing the
target, whereas that target would be eliminated if both vowels were harmonic
and had the same F0. Another possible explanation is that other mechanisms are
at work in addition to cancellation.Lea (1992) also found evidence for cancellation: when the target was a 112 Hz voiced vowel, identification rates were better by 3% for a 100 Hz voiced ground than for a whispered ground. When the target was a whispered vowel, the advantage was 8%. Subsequent experiments (Lea and Tsuzaki 1993a,b) gave similar results. The largest effect found by Lea (1992) was greater by a factor of 2.7 than the ground harmonicity effects we found (~3%). The smaller size of our effects may be due to the fact that our inharmonic vowels were more "harmonic" than whispered vowels.
An explanation for the apparent preference of the auditory system for
cancellation over enhancement may be found in an experiment by McKeown (1992).
He requested subjects to identify both vowels within a pair, and at the same
time judge which vowel was "dominant", and which was "dominated". Improvements
in identification with F0 only concerned the dominated vowel. If we
suppose that it is easier to estimate the F0 of a dominant vowel than that of a
dominated vowel, it should follow that cancellation is easier to apply to
segregate the dominated vowel (de Cheveigné 1993a). It is then
reasonable that factors upon which cancellation depends should affect the
scores. Another explanation may be found in an experiment of de
Cheveigné (1993b, 1994). Harmonic enhancement and cancellation were
implemented in a speech recognition system to reduce the effects of co-channel
speech interference. Cancellation was more effective than enhancement,
presumably because it was less affected by the non-stationarity of speech. The
synthetic vowels used in our experiments are stationary so this consideration
should not apply here. However, the auditory system may have evolved to use
only strategies that are robust for natural stimuli.
The harmonic sieve employed by spectral models based on Parson's harmonic selection method (Assmann and Summerfield 1990; Parsons 1976; Scheffers 1983; Stubbs and Summerfield 1988, 1990, 1991) can be used in either of two modes: to retain components that fall close to a harmonic series, or else to remove them. These modes correspond to enhancement and cancellation, respectively. The sieve may be applied in turn for each F0, correlates of one voice being selected among those rejected by the sieve tuned to the other. In that case each voice retrieved is actually a product of both strategies. Similar remarks can be made concerning models derived from Weintraub's spectro-temporal model (Assmann and Summerfield 1990; Lea 1992; Meddis and Hewitt 1992; Weintraub 1985): channels dominated by the period of a voice can be retained (enhancement) or else removed (cancellation). If both operations are applied in turn, each voice retrieved is really the product of both strategies. In the model of Meddis and Hewitt (1992), only one F0 was used, so one voice (the dominant one) was purely the product of enhancement, whereas the other voice was purely the product of cancellation. However nothing in the model prevents it from being extended to use both strategies to segregate both voices. Finally, de Cheveigné (1993a) proposed a time-domain comb-filtering model implemented by neural circuits involving inhibition that was capable of either enhancement or cancellation.
Since most models allow both strategies, our results do not allow us to choose among them, but they do allow us to better understand how each model functions.
F0. Summerfield
and Assmann (1991) suggested that such an improvement might be explained by
misalignment between partials of constituent vowels. At unison the partials of
both vowels coincide, and their relative contributions to the combined spectrum
are obscured by phase-dependent vector summation. Misaligned partials on the
other hand may show up as independent peaks within a high-resolution spectrum
and thus template-matching strategies might be more successful. Summerfield and
Assmann (1991) found some evidence for an effect of component misalignment for
vowels with widely-spaced components (200 Hz), but none for monaurally
presented vowels at 100 Hz. On the other hand in a masking experiment in which
thresholds were determined for synthetic vowels masked by vowel-like maskers,
Summerfield (1992) attributed up to 9 dB of a 17 dB release from masking to
component misalignment. The remaining 8 dB were attributed to F0-guided
mechanisms. Our results certainly cannot be explained solely in terms of
component misalignment. HI and IH conditions involve the same inter-component
intervals, yet they produce identification rates that are very different.
However if harmonic misalignment were involved together with other mechanisms,
it might help explain for example why the HH0 condition was significantly worse
than the HI0 condition. Our experiments used II pairs in which the inharmonic
patterns of the vowels were different, and thus partials did not coincide at
nominal F0=0. It would be worth investigating a similar condition in
which both vowels have the same inharmonic pattern. Comparisons between
the two would allow us to factor out eventual effects of component
misalignment.If the period of a vowel is long relative to time constants of integration within the auditory system, the vowel's auditory representation may fluctuate during the period. Mutual interference between concurrent vowels may be more or less severe according to whether the fluctuations of their respective representations line up in time or not. A small F0 difference is equivalent to a gradually increasing delay of one vowel relative to the other, and this might allow the auditory system to select some favorable interval on which to base identification. Differences in F0 might thus enhance identification. Summerfield and Assmann (1991) investigated the effects of pitch period asynchrony on identification rate using vowels with same F0 but varying degrees of phase shift. They found a significant effect at 50 Hz, but none at 100 Hz, presumably because the integrating properties of the auditory representation smooth out fluctuations at this rate. Our vowels had even higher F0s, so this explanation is unlikely to account for our data.
Slower fluctuations may occur in the compound representation of the
vowel pair. Two partials falling within the same peripheral channel produce
beats with a depth that depends on their relative amplitudes, and a rate equal
to their difference frequency. Three or more partials produce yet more complex
interactions. These fluctuations may cause the auditory representation to take
on a shape that momentarily allows one vowel or the other, or both together, to
be better identified. Culling and Darwin (1993a,b) suggested that such beats
might explain increases of identification rate with differences in F0. Assmann
and Summerfield (1994) found that successive 50 ms segments excised from a 200
ms stimulus composed of two vowels with different F0s were not equally
identifiable. For small F0, identification of the whole stimulus
could be accounted for assuming it was based on the "best" of the segments that
composed it. This result is compatible with the notion that F0 differences
cause the auditory representation to fluctuate (as does, indeed, the short-term
spectrum itself), and provide the auditory system with various intervals upon
which to base identification, one of which may be particularly favorable to
either vowel or both.
Inharmonicity or F0 differences between vowels can be interpreted as slowly varying phase relationships between partials of harmonic vowels with a same F0. The "best interval" provided by beating can be interpreted simply as a phase relationship that is particularly favorable for identification. The harmonic vowels used in our experiments were all synthesized in sine phase, whereas the partials of inharmonic vowels can be interpreted as progressively moving out of this phase relationship. If the masking power of vowels in sine-phase is relatively small and the resistance to masking of vowels in sine-phase is relatively poor, then harmonic vowels will appear to be both less well recognized and less effective as maskers, as indeed we found. Phase effects thus constitute a possible alternative explanation of our results.
F0s, from which Culling and
Darwin concluded that a common F0 between formants does not affect how
they are grouped together. Our results go a step further. They suggest that a
common F0 between partials has no positive effect (and apparently even a
negative effect) on the identification of the sound that they form. This result
is counter-intuitive, and is contradicted by some other studies. For example,
Darwin and Gardner (1986) found that mistuning a single partial within a
formant affected the phonetic quality of a vowel. However the effect of
mistuning (which was phase-dependent) was not always in the direction expected
on the basis of harmonic grouping. A common F0 does have one important effect: it produces the impression of a single source. The presence of multiple F0s within a sound, what Marin (1991) calls "polyperiodicity", produces the impression of multiple sources, and thus signals to the auditory system that segregation is called for. This signal might have great value for sound organization, and yet have no effect in psychoacoustic experiments for which the listening frame is already determined by the task.
F0=0, in which case the advantage was 8%. This result is
contrary to what one would expect if a strategy of harmonic enhancement was
used to segregate the vowels.
2) Listeners identified vowels within synthetic pairs better by about 3% when
the vowels accompanying them were harmonic than when they were inharmonic,
except when the target vowel was also harmonic and F0=0, in which case
they were less well identified by about 3%. These results are consistent
with the hypothesis of harmonic cancellation.
3) When both vowels within a pair were harmonic, they were better identified by about 6% when there was a difference in F0 of 1/2 semitone. This is consistent with results of previous studies. When either vowel was inharmonic, a difference in F0 did not affect identification.
4) When one vowel within a pair was harmonic and the other inharmonic, the inharmonic component was identified significantly better than the harmonic component. Effects do not follow the symmetric pattern that is sometimes assumed to be characteristic of primitive segregation.
5) Our experiments employed a particular starting phase pattern (sine) to synthesize all vowels. In the light of recent results that demonstrate the role of beats in the identification of concurrent vowels (Assmann and Summerfield 1993, Culling and Darwin 1993b), we cannot rule out the possibility that our results are partly specific to this phase pattern.
Fundamental frequency had two putative roles for Darwin (1981): to "group consecutive sounds together into the continuing speech of a single talker" and to "group together the harmonics from different formants of one talker, to the exclusion of harmonics from other sources" (p. 186). Our results suggest that these roles are minor in comparison to a third: to group together components that belong to an interfering source to better eliminate it. The lack of benefit of target harmonicity for identification is surprising, as target harmonicity can in principle be exploited by a majority of harmonic sound separation models. The question merits further examination, perhaps using tasks that do not trigger cancellation.
1) Choose an initial 10-point reference set. The first point is chosen at random, each following point is chosen as far away as possible from previously chosen points.
2) Partition the set into clusters, assigning each data point to its closest reference.
3) Replace each reference by the centroid of its cluster, then loop to 2) until a convergence criterion is met.
4) For each centroid finally obtained, choose the closest original data point.
The result was a set of 50 allophones, 10 for each vowel.
We repeatedly met difficulties with /u/. For some reason, very few portions of speech isolated from our database sounded like /u/ after resynthesis, even those taken from sentences labelled as containing mainly /u/ phonemes. A tentative explanation is that in French /u/ is articulated with a protrusion of the lips. The target position may require some time to be attained, and the resulting spectral transition may in fact be necessary for identification. Evidently no such transition is present in the resynthesized vowel. This does not explain however why a few tokens do sound reasonably /u/-like after synthesis. Overall, surprisingly few of the original voiced speech tokens were identified consistently as vowels after resynthesis: less than 10 % of the original tokens survived the final screening. In real speech vowel identity is probably largely determined by contextual or dynamic features that are absent from the resynthesized vowels (Hillenbrand and Gayvert 1993).
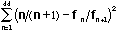
where fn is the frequency of the nth component.
We first determined informally, for each of the 10 vowel pairs, the rms level differences for which either vowel appeared to be absent. We then centered a scale with 4 dB steps and 10 levels on the mean of these two differences, and synthesized pairs of unison harmonic vowels according to this scale. There were 10 such scales, one for each different vowel pair. The stimuli were presented 5 times each in random order to four subjects (the four authors). At each presentation the stimulus was repeated twice; after each repetition the subject had to identify one constituent (SRSR pattern). A response could be any of the five vowels, or 'x' if no vowel could be heard, but the two responses had to be different. Psychometric functions were plotted for each component of a pair, and their intercept was taken as the corrective factor (more sophisticated interpolation techniques were judged unnecessary for our purpose of adjusting levels to avoid complete dominance within a pair). The corrective factors for all pairs are shown in Table A3-I
| /e/ | /i/ | /o/ | /u/ | |
|---|---|---|---|---|
| /a/ | -5.0 | -7.5 | -17.5 | -31.0 |
| /e/ | 1.0 | -11.5 | -17.0 | |
| /i/ | -2.0 | -16.0 | ||
| /o/ | -16.5 |
Table A3-I Level correction factors for vowel pairs, in dB.
The level after correction of one vowel relative to another is shown at the
intersection of the row and column that they label, respectively. For example
to synthesize /ae/ the rms level of /a/ should be set to be 5.0 dB less than
that for /e/.
These results are roughly compatible with those reported by McKeown (1992) for
three of his four subjects: /a/ tends to dominate all other phonemes, /u/ tends
to be dominated by all others. Other phonemes are intermediate: /o/, /i/, /e/
in order of increasing dominance. However, our factors were determined before
the final screening that eliminated four allophones of /u/. Levels are
therefore certainly biased too far in favor of /u/ to compensate for their poor
quality. This is evident in the rates as a function of ground vowel,
particularly low when /u/ is ground (III-D-6), but it should not affect our
main conclusions concerning the effects of harmonicity or F0: they
remain quite similar when pairs containing /u/ are removed from analysis. We do
not recommend that these particular level correction factors be used in other
studies.
Assmann, P. F. and Summerfield, Q. (1990). "Modeling the perception of concurrent vowels: vowels with different fundamental frequencies," J. Acoust. Soc. Am. 88, 680-697.
Assmann, P. F. and Summerfield, Q. (1994). "The contribution of waveform interactions to the perception of concurrent vowels," J. Acoust. Soc. Am. 95, 471-484.
Bregman, A. S. (1990). Auditory scene analysis (MIT Press, Cambridge, Mass.).
Broadbent, D. E. and Ladefoged, P. (1957). "On the fusion of sounds reaching different sense organs," J. Acoust. Soc. Am. 29, 708-710.
Brokx, J. P. L. and Nooteboom, S. G. (1982). "Intonation and the perceptual separation of simultaneous voices," Journal of Phonetics 10, 23-36.
Carlyon, R. P. (1991). "Discriminating between coherent and incoherent frequency modulation of complex tones," J. Acoust. Soc. Am. 89, 329-340.
Cherry, E. C. (1953). "Some experiments on the recognition of speech with one, and with two ears," J. Acoust. Soc. Am. 25, 975-979.
Childers, D. G. and Lee, C. K. (1987). "Co-channel speech separation", IEEE ICASSP, 181-184.
Culling, J. (1990). "Exploring the conditions for the perceptual segregation of concurrent voices using F0 differences," Proc. of the Institute of Acoustics 12, 559-566.
Culling, J. F. and Darwin, C. J. (1993a). "Perceptual separation of simultaneous vowels: within and across-formant grouping by F0," J. Acoust. Soc. Am. 93, 3454-3467.
Culling, J. F. and Darwin, C. J. (1993b). "Perceptual and computational separation of simultaneous vowels: cues arising from low frequency beating," draft submitted for publication.
Darwin, C. J. (1981). "Perceptual grouping of speech components differing in fundamental frequency and onset-time," Q. J. Exp. Psychol. 33A, 185-207.
Darwin, C. J. and Culling, J. F. (1990). "Speech perception seen through the ear," Speech Communication 9, 469-475.
Darwin, C. J. and Gardner, R. B. (1986). "Mistuning of a harmonic of a vowel: grouping and phase effects on vowel quality," J. Acoust. Soc. Am. 79, 838-845.
de Cheveigné, A. (1993a). "Separation of concurrent harmonic sounds: Fundamental frequency estimation and a time-domain cancellation model of auditory processing.," J. Acoust. Soc. Am. 93, 3271-3290.
de Cheveigné, A. (1993b). "Time-domain comb filtering for speech separation", ATR Human Information Processing Laboratories technical report TR-H-016.
de Cheveigné, A., Kawahara, H., Aikawa, K., and Lea, A. (1994). "Speech separation for speech recognition", Proc. 3rd French Congress of Acoustics, Toulouse, 1994.
Demany, L. and Semal, C. (1990). "The effect of vibrato on the recognition of masked vowels," Perception & Psychophysics 48, 436-444.
Denbigh, P. N. and Zhao, J. (1992). "Pitch extraction and separation of overlapping speech," Speech Communication 11, 119-125.
Frazier, R. H., Samsam, S., Braida, L. D., and Oppenheim, A. V.. (1976). "Enhancement of speech by adaptive filtering", IEEE ICASSP, 251-253.
GRECO, (1987). "BDSONS, base de donnees des sons du francais, GRECO1", edited by Jean-Francois Serignat and Ofelia Cervantes, ICP, Grenoble (France).
Hanson, B. A. and Wong, D. Y. (1984). "The harmonic magnitude suppression (HMS) technique for intelligibility enhancement in the presence of interfering noise", IEEE ICASSP 2, 18A.5.1-4.
Hillenbrand, J. and Gayvert, R. T. (1993). "Identification of steady-state vowels synthesized from the Peterson and Barney measurements.," J. Acoust. Soc. Am. 94, 668-674.
Lea, A. (1992). "Auditory models of vowel perception", unpublished doctoral dissertation (University of Nottingham, UK).
Lea, A. and Tsuzaki, M. (1993a). "Segregation of competing voices: perceptual experiments," Proc. Acoust. Soc. Jap., Spring session, 361-362.
Lea, A. P. and Tsuzaki, M. (1993b). " Segregation of voiced and whispered concurrent vowels in English and Japanese," J. Acoust. Soc. Am. 93, 2403 (A).
Lea, A. P. and Summerfield, Q. (1992). "Monaural segregation of competing voices," Proc. Acoust. Soc. Japan committee on Hearing H-92-31, 1-7.
Marin, C. (1991). "Processus de séparation perceptive des sources sonores simultanées", unpublished doctoral dissertation (Université de Paris III, France).
Marin, C. and McAdams, S. (1991). "Segregation of concurrent sounds. II: Effects of spectral envelope tracing, frequency modulation coherence, and frequency modulation width," J. Acoust. Soc. Am. 89, 341-351.
McAdams, S. (1989). "Segregation of concurrent sounds. I: Effects of frequency modulation coherence," J. Acoust. Soc. Am. 86, 2148-2159.
McKeown, J. D. (1992). "Perception of concurrent vowels: the effect of varying their relative level," Speech Communication 11, 1-13.
Meddis, R. and Hewitt, M. J. (1992). "Modeling the identification of concurrent vowels with different fundamental frequencies," J. Acoust. Soc. Am. 91, 233-245.
Moore, B. C. J., Glasberg, B. R., and Peters, R. W. (1985). "Relative dominance of individual partials in determining the pitch of complex tones," J. Acoust. Soc. Am. 77, 1853-1860.
Naylor, J. A. and Boll, S. F. (1987). "Techniques for suppression of an interfering talker in co-channel speech", IEEE ICASSP, 205-208.
Parsons, T. W. (1976). "Separation of speech from interfering speech by means of harmonic selection," J. Acoust. Soc. Am. 60, 911-918.
Scheffers, M. T. M. (1983). "Sifting vowels", unpublished doctoral dissertation (University of Gröningen, the Netherlands).
Stubbs, R. J. and Summerfield, Q. (1988). "Evaluation of two voice-separation algorithms using normal-hearing and hearing-impaired listeners," J. Acoust. Soc. Am. 84, 1236-1249.
Stubbs, R. J. and Summerfield, Q. (1990). "Algorithms for separating the speech of interfering talkers: evaluations with voiced sentences, and normal-hearing and hearing-impaired listeners," J. Acoust. Soc. Am. 87, 359-372.
Stubbs, R. J. and Summerfield, Q. (1991). "Effects of signal-to-noise ratio, signal periodicity, and degree of hearing impairment on the performance of voice-separation algorithms," J. Acoust. Soc. Am. 89, 1383-1393.
Summerfield, Q. (1992). "Roles of harmonicity and coherent frequency modulation in auditory grouping," in The auditory processing of speech, edited by B. Schouten (Mouton deGruyter, Berlin), 157-165.
Summerfield, Q. and Assmann, P. F. (1991). "Perception of concurrent vowels: effects of harmonic misalignment and pitch-period asynchrony," J. Acoust. Soc. Am. 89, 1364-1377.
Summerfield, Q. and Culling, J. F. (1992). "Auditory segregation of competing voices: absence of effects of FM or AM coherence," Phil. Trans. R. Soc. Lond. B 336, 357-366.
Weintraub, M. (1985). "A theory and computational model of auditory monaural sound separation", unpublished doctoral dissertation (Stanford University, USA).
Zwicker, U. T. (1984). "Auditory recognition of diotic and dichotic vowel pairs," Speech Communication 3, 256-277.
____________________________
Server © IRCAM-CGP, 1996-2008 - file updated on .
____________________________
Serveur © IRCAM-CGP, 1996-2008 - document mis à jour le .