
Tous droits réservés pour tous pays. All rights reserved.
| Serveur © IRCAM - CENTRE POMPIDOU 1996-2005. Tous droits réservés pour tous pays. All rights reserved. |
Rapport Ircam 25/80, 1980
Copyright © Ircam - Centre Georges-Pompidou 1998
It is now twenty years since Max V. Mathews and his team at Bell Telephon Laboratories in the USA began their experiments with computer programs for digital sound synthesis and over ten years since the appearance of the first serious compositions. A number of different but nevertheless closely related programs, compilers and systems for computer music synthesis have been developed during this period. Some of them, notably MUSIC 5 and MUSIC 360, have already been used quite widely. Although there is continuing need for development, the Seventies have seen the establishment at IRCAM (Paris), Stanford Artificial Intelligence Laboratory, Princeton University, M.I.T. and other centres in North America of relatively stable and well-defined systems. This together with the advent quite recently of the digital synthesiser, which is causing designers of digital sound synthesis systems to reconsider their ideas and plans, suggests that computer music is entering a new stage where more and more composers not necessarily familiar with computing techniques will be able to use the systems. The arrival of composers with a broad musical outlook can only prove beneficial in bringing about the development of installations more closely geared to the needs of musicians.One area where composers are beginning to have more and more influence is in the development of facilities for processing prerecorded material with the computer. Hitherto the overriding tendancy has been to use the computer as a synthesiser building more or less complex sounds from basic building blocks. In his "Introductory Catalogue of Computer Synthesized Sounds" Jean-Claude Risset demonstrated how instrument-like and new sounds could be synthesised according to basic acoustic principles. However, the computer can be used to simulate all the functions of the conventional sound studio, and in this report I shall describe some of the possibilities for treating 'concrete' prerecorded material. Although I will discuss these in terms of the MUSIC 5 system set up on the DEC PDP-10 computer in the Computer Department at IRCAM, most of the established sound synthesis programs, such as MUSIC 360, MUSIC 10 and MUSIC 11, have modules for reading in sound files input via analogue-to-digital convertors, and some of the ideas presented will be transportable to systems employing the other sound synthesis languages.
I would like to thank Jean-Claude Risset and the Computer Department for giving me the opportunity to use IRCAM's facilities and James Anderson Moorer for his frequent and patient advice.
Stanley Haynes, January 1979
The first generation of computer synthesised music, which includes some fine pieces by Jean-Claude Risset, John Chowning, Barry Vercoe, J. K. Randall and others, consists of works which use the computer as a sound synthesiser. Even where live instruments play together with the tape, as in the case of Risset's "Dialogues" for flute, clarinet, piano & percussion or my own "Pyramids-Prisms" for piano & tape, and it is desired to make reference to the instrumental sounds when creating the tape, these are synthesised using additive synthesis or one of the global synthesis methods, such as frequency modulation or non-linear distortion. Recently a number of centres in North America and IRCAM in Paris have been able to set up relatively stable and well documented systems. These are much more accessable and as a result are being used by a new generation of composers who are not necessarily familiar with computing techniques. There is increasingly a desire to be able to process prerecorded material with the computer, and most of the sound synthesis languages include facilities for reading computer files created by digitising sound with analogue-to-digital convertors. The MUSIC 5 system set up on the DEC PDP-10 computer at IRCAM has some particularly powerful features, and I will discuss some of the possibilities and problems I have become aware of using this system. I will also refer to my work on the realisation of York Höller's "Arcus" for 17 instruments and computer-transformed tape during the summer of 1978, but this is more fully discussed in my "Report on the Realisation of York Höller's ARCUS" (December, 1978), which is available from IRCAM.
The digitised sound files are usually stored in IRCAM's PDP-10 system on special disc packs allocated to a particular project or on one of the system discs. The files are read by Music 5 using the modules LUM, LUS, LUQ and LUC, which have been designed and implemented by Jean-Louis Richer who, since the autumn of 1977, has been responsible for the maintenance and further development of the Music 5 system. LUM is used to read mono sound files, LUS for stereo and LUQ for quad, while LUC can be used to read an individual channel of a stereo or quad file. Up to 15 input sound files at a time can be defined by the user using the FIC command, which has the following syntax :
The particular example shown above allocates a file reference number (ficnr) 1 to the file MUSIC.MSB at time zero (ie. the beginning of the section). When all 15 reference numbers are exhausted or if for some other reason it is later desired to reuse a reference number, an allocation of the type shown above can be cancelled using an FER command. The reference number can then be allocated to another file using an FIC with the appropriate action time specified in the (time) parameter (P2).
FIC (time) (ficnr) (filename); eg: FIC 0 1 MUSIC.MSB;
The read-in modules use buffers in Pass 3 of Music 5 to store sound samples and the larger these are the faster the samples can be transferred from the disc. However, large buffers in Pass 3 increase its size, and often it is necessary to establish a trade-off between the space in the computer occupied by the program and the speed at which sound files can be read. This can be achieved using the LON command, whose 2nd parameter permits the size of each buffer to be specified in multiples of 128 words. The number of buffers may also be specified using an NTA command. In general one buffer must be allocated for each file which is being simultaneously read. At present buffers are released only at the end of a section but Music 5 is being modified so that they are released at the end of each NOTE. The system sets the number of buffers by default to 5 and their length to 512 words if the NTA and LON commands are not used.
A more extended discussion of the Music 5 sound input facilities can be found in Jean-Louis Richer's "Manuel do Music 5" (IRCAM, 1978) so I will confine myself to a description of the syntax of the LUM module, which is the basis of the examples presented later ;
LUM (amp) (freq) (outp) (ficnr) (st ) (liml) (lim2);
To calculate an amplitude envelope it is often sufficient to take a simple average of the digital samples of the rectified wave. In more demanding case it may be necessary to employ algorithms which are dependent on the rate at which successive sample values change. For the processing of York Höller's "Arcus" it was necessary to synchronise changes in the parameters of the transformation with the beginning of notes recorded by the instrumentalists. The most practical way to achieve this was to supply Pass I of Music 5 with information about the begin and end times of notes in the digitised sound file and use a compositional (PLF) subroutine to create NOTE statements with the appropriate action times, durations and other parameter fields to control the sound transformation. The data needed by the PLF routine was created by a preliminary run of Music 5 using the 'score' presented on page 6 and a special Pass 3 subroutine (PLT), written by Jean-Louis Richer, which is called each time the module "APP" is encountered within the Music 5 instrument. The PLT is listed in Appendix 1 and can also be found in IRCAM's PDP-10 system in the file PLTSH.POR((DOC,SH3)). Its function is to request and read certain control variables from the terminal and to print results both to the terminal and to a file, TEMPS.DAT, which is later read by the PLF routine during the sound processing run. Together with its associated Music 5 score, PLTSH forms a simple envelope detector, which works by taking the average of the digital samples of the rectified wave within a window whose size (in samples) can be specified by the user. This average, representing the instantaneous value of the amplitude envelope at that time instant, is then compared (at < 5 >) with values (DEB and FNOTE), which represent thresholds at which we wish to define a sound as having begun or ended. These are necessary because even in the so-called silences between notes small sample values are generated as a result of recording noise. Music 5 amplitudes are expressed on a scale of 0 to 2047, and the setting of values for the thresholds is quite critical. For the instrumental tracks used as source material for "Arcus" onset threshold settings ranged from 10 to 45 and those for the end threshold from 5 to 15, but the most typical settings were about 25 for onset and 7 for end. Settings for the window size were much less critical, and a value of 250 samples was usually adopted. However, since Pass 3 is implemented in fixed point arithmetic, some of the louder tracks produced integer overflows (ie : calculated values exceeding the maximum integer which can be handled by the computer) when 250 samples were summed prior to taking their average, and for these files a 120-sample window was used.
Figure 1 shows a 250-sample window positioned across the beginning of a sound, and it should be evident that in this situation the first 250 or so samples will be summed with small values representing the end of the preceding silence and a small average will be calculated by the MFF module. In most cases it is not until the window is almost completely within the sound that averages approaching the threshold are produced. By this time the correct beginning might be up to 250 samples earlier. A similar effect occurs at the end, which is likely to be later than calculated. The special Pass 3 subroutine (PLTSH) compensates for these errors by requesting the user to give at the terminal values, expressed in samples, to offset the begin and end times. For the instrumental tracks of "Arcus" we used -200 and +200 respectively as our beginning and end offsets when using a 250-sample window and -100 and +100 for 120-sample windows.
The detector described above, though developed for the processing of York Höller's "Arcus", should be usable for other projects. However, it must be borne in mind that it is of comparatively simple design and is fairly sensitive to the type of sounds which are input. Indeed, the timbre can be almost as significant as the amplitude in requiring changes of threshold settings, window size, etc. Since the detector responds to the average of individual samples, the shape of the waveform and in particular the amount of time it is close to the zero axis can be crucially important. A square wave, which has comparatively few samples close to zero, will give higher average readings than a more gently sloping ramp or sinusoidal waveform. Although we had to experiment to find threshold settings appropriate for particular files, we were fortunate in that the "Arcus" tracks were made up of predominantly homogeneous material and were usually restricted to instruments of a similar type. It might well have been difficult to find settings appropriate to a track containing a mixture of piccolo, contrabassoon and string quartet sections. Moreover, sounds to be detected as separate events must be isolated from one another by a silence at least as large as the window, and piano notes whose attack overlaps the resonance of earlier notes, sustained with the pedal, will not be detected as a new event. Quite a lot of experimentation is required to get the detector's control parameters right, and it usually takes more time and effort both for the programmer and the computer to extract the timing information than to perform the sound transformation itself.Figure 1
250-sample window positioned across the beginning of a sound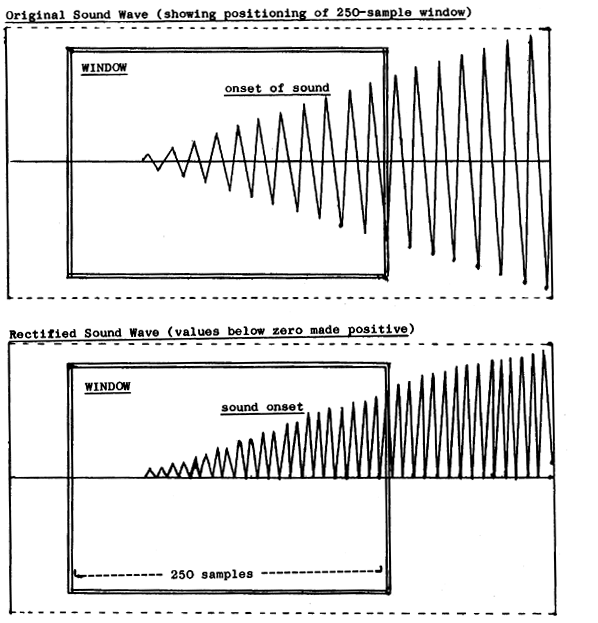
Music 5 'score' for detecting the beginning and end of sounds in an input file

The timing data produced by the detector is necessarily relative to the beginning of the source sound file, which may well contain superfluous material before the first desired sound. Often it is necessary to synchronise more than one file and a common timing reference must be established. The method employed when recording the instrumental source material for "Arcus" was to record 8 timing clicks in tempo before the opening of each track. During the detector run these clicks were identified, the time interval between them calculated and a 'reference start time' calculated one half beat before the desired opening of the track. This reference time, which was included as part of the information in TEMPS.DAT, was then used by the PLF routine as time zero in the output file, and all tracks processed in this way had a common reference time and could be synchronised without difficulty.
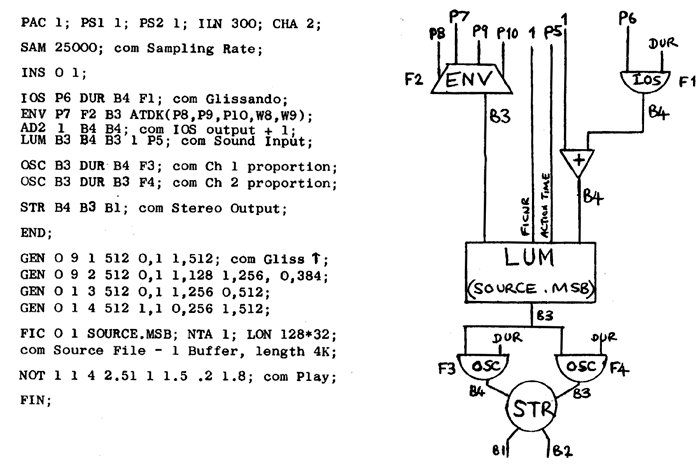
The computer can simulate the analogue sound studio with both greater purity of timbre and superior accuracy. An example which very much demanded these occurs in Section 29 - Track 4 of Höller's "Arcus". It consists of a succession of very fast semiquavers in the piano part which the composer wished to ring modulate using a fresh value of the pitch series for each of the piano's notes. The precision required to realise this section would be impossible in a manually controlled studio and exceedingly difficult even using a computer-controlled synthesiser such as the one set up at the EMS Foundation in Stockholm. It was realised without too much difficulty at IRCAM using the detector and PLF subroutine described earlier controlled by the Music 5 score overleaf. The range of the pitch series stored within the PLF routine is expanded to cover two octaves and for each note successive values are extracted from the series beginning with the first element transposed to 116.54 Hz, which is the pitch of the B flat a ninth below middle C with which the piano part begins. The serial pitches are assigned to parameter field 6 (P6) of the NOTE statements produced by the routine and are used to control the frequency of an oscillator (OSC) generating a sinewave (Fl) within the Music 5 instrument. The oscillator's output (B4) is then multiplied (MLT) with the output (B3) of the sound input module (LUM), reading from the source sound file SHH:T29P4.MSB, to produce the ring modulated output (B3). This is then transferred to the output file by the OUT module.
Music 5 Score for Ring Modulated Piano (Section 29 of "Arcus")

Notice that the glissando control curve (B4) produced by the interpolating oscillator is added to 1. Since the oscillator's amplitude (P6 of the NOTE) is 1 and the function (F1) is cycled once per note,(*) the relative rate at which the input file is read increases exponentially from 1 to 2 during the course of the note to produce a glissando beginning at the original pitch and ascending one octave. Also, 2 oscillators (OSC) have been added to the instrument to control the spatial distribution of the sound output (B3) from the LUM. Each of them multiplies B3 by a function (F3 and F4 respectively), which is generated by function generator 1 (GEN 0 1 .... etc.). This produces linear curves, as opposed to the exponential ones produced by GEN 9. Since the curves F3 and F4 are mirror images of one another, the outputs (B4 & B3) of the oscillators when sent to two output channels produce a stereophonic image which moves from one speaker to the other and then back again during the course of the note. The 7th parameter (P7) of the NOTE statement specifies an amplitude scalar, in this case 1.5, which is sustained throughout the steady-state portion of the envelope. The amplitude of sounds in the file will then be multiplied by 1.5 and by a proportion thereof during the attack and decay portions of the envelope curve.Music 5 Score to Re-envelope and apply Glissando to an Input File
Although a NOTE statement is used to initiate the process, the file-segment read need not necessarily contain only a single note or sound. Often there are several and it is then their global amplitude and frequency which is controlled by the LUM scalars. If, for instance, a global glissando is applied to a file which already contains a recorded glissando, the glissandi will cancel or reinforce one another according to whether they move in the same direction. If automatic envelope detection is used to derive the global control parameters, some extremely supple effects can be achieved, which would be far beyond the scope of a manual system. The Music 5 score shown below can be used to extract a segment from a sound file, which we will assume to contain a slowly decaying tam tam sound (TAMTAM.MSB), and then loop the segment as smoothly as possible. To achieve this it is necessary to compensate as much as possible for the amplitude variation brought about by the decaying tam tam in the source file-segment, which in this case begins 1" after the attack and lasts 2.5", by using an envelope follower within the processing instrument. Notice also that the loop playing facility of the LUM module is brought into play by specifying a negative file reference number :
The NOT statement controls what happens in the output file. Its 2nd parameter P2, in this case .5", determines the time at which the loop is to be started with respect to the beginning of the section, P4 represents the duration (9.5") for which the sound is to be looped, while P7 and P8 respectively represent the beginning and end of the segment to be looped, expressed in seconds with respect to the beginning of the input sound file. P5 is a scaler (1.5) used to multiply the amplitude of the source file, and P6 (1200) represents a reference to which the averages produced by the MFF module are compared. The resulting amplitude modifying factor is used to multiply individual samples of the incoming signal so as to compensate for the tam tam's decay and hopefully produce a more or less steady signal with an average amplitude of 1200 (on the scale 0 to 2047). Some experimentation will be necessary to find the optimum size for the window used to average the samples. I have suggested a size of 250 samples because a tam tam sound might well have significant energy down to 50 Hz. At the sampling rate of 25000 per second, 250 samples represent one hundredth of a second and would encompass one half cycle of a wave at 50 Hz. This window size is the minimum which will produce reasonably accurate averages for sounds with components in this pitch domain.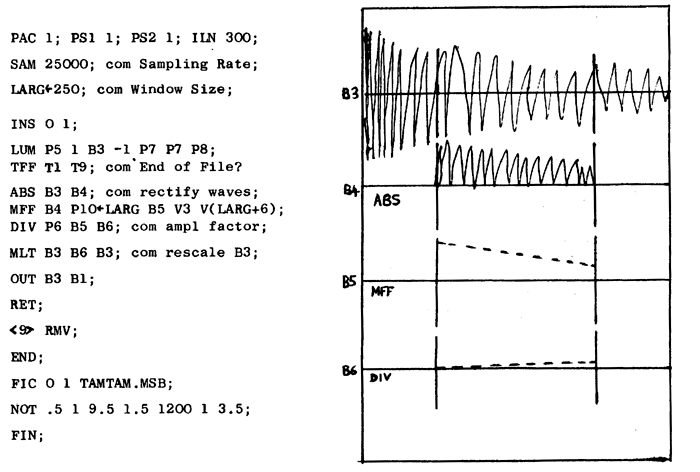
An important factor to be borne in mind when modifying the envelope of a source sound file is that the recording noise, which sometimes accompanies the quieter sounds, is amplified together with the desired signal, and so excessive amplification of very quiet sounds must usually be avoided. Also, averaging techniques cannot by their very nature take into account the minute details which can be very significant with respect to individual samples. The Music 5 score quoted earlier will almost undoubtedly give rise to audible discontinuities in the sound when the beginning of the loop takes over from the end of a previous presentation. These can be almost perfectly disguised by overlapping the loops, using separate NOTE statements for each repetition. In the Music 5 score presented overleaf an interpolating oscillator (IOS) and multiplier (MLT) have been added at the end of the instrument to multiply the smoothed signal by a 'bell-shaped' curve (Fl) generated by function generator number 7 (GEN 0 7 1 512 0;), which is cycled once per note (loop). Each repetition of the loop arrives and disappears very smoothly and, if they are carefully overlapped an absolutely smooth sound will result. Theoretically, beginning each repetition half-way through the preceding loop should produce acceptably smooth results, but changes of phase in the overlap portion often cause dislocations. However, the NOTE's are staggered in this way in the next example :
Music 5 Score to extract a Segment and Re-envelope it with Overlaps

The restriction of the source material for a composition to comparatively few phrases and individual sounds means that, in the former case, the detector need not be run so often since the extracted timing data can be used several times and can, if necessary, be modified using changes of tempo, accelerandi, ritardandi, etc. during the sound processing run. Sound files containing a single sound or a group which is to be processed globally can be edited using programs such as the interactive sound editor "S" at IRCAM so that the superfluous material preceding and following the sound(s) in the file can be removed. This can be quite time-consuming and is much more practical when there are comparatively few files, which are to be used several times. Once stored in digital form on the system discs, the sound files can be played forwards or backwards at any fixed or varying rate and can be transformed using all the processing power of languages such as Music 5. At IRCAM sound files can be digitally filtered, reverberated, delayed, amplitude and frequency modulated with waveforms produced by digitally simulated oscillators or with one another and re-enveloped in the manner described earlier. The transformation process can be so extreme as to completely mask the true origins of the sounds, and an appropriately selected source sound can generate a palette rich enough to serve for long sections of a piece. The transformed sounds can then be digitally mixed, spatialised and also placed with great precision in their correct temporal relationships in the output file. Even the tape for "Arcus", which consisted of transformed instrumental material to be synchronised with the live ensemble during performance, could have been made in this way had the source material been recorded with greater economy.
Analysis-based synthesis works by tracking the amplitude envelope of each of the harmonic components of a sound and thus produces vast amounts of data. A data-reduction method which has proved quite successful is to fit the functions representing the amplitude and slight frequency variation for each harmonic with piecewise-linear functions. This is described in John M. Grey's Ph D thesis "An Exploration of Musical Timbre" (Stanford, 1975). The functions were fitted by hand with the aid of an interactive sound viewing program, but more recently at IRCAM James A. Moorer has developed a suite of programs which determine the fundamental frequency, an essential first step prior to analysing the evolution of the components, and then present information on the pitch and amplitude envelopes for each harmonic in a form which can be used directly by the MUSIC 10 sound synthesis language to generate control functions. These are then used to control a bank of computer-simulated oscillators, which can be used to reproduce sounds which are all but indistinguishable from the original. If the control functions are modified new sounds are produced, and it is possible to interpolate between the functions of two different source sounds to produce transitions.
It is also possible to merge spectra by 'splicing' sets of control functions. The evolution of the spectra can be modified either by changing the functions or by multiplying them with modifying functions produced by oscillators within the computer instrument. This gives the possibility to begin with a recognisably instrumental or vocal sound and gradually shift the amplitude and frequency of each harmonic component to produce a new spectrum. Jonathan Harvey has exploited these effects using the computer-controlled analogue synthesiser in Stockholm for his "Inner Light I" for ensemble with tape and "Inner Light III" for orchestra with tape, creating instrument-like tones whose harmonic components fan out and equalise in amplitude to come to rest on chords. This technique can be used with even greater precision on an all-digital system. However, the sounds to be analysed must have a reasonably constant fundamental frequency and a harmonic spectrum, which means that instruments played with vibrato can pose problems.
Since both of the analysis/resynthesis systems described create intermediate data which is then used to control the regeneration of the sound, they allow more independent control of sound parameters. One of the more obvious applications is in the transposition of the fundamental frequency of sounds without changing their duration. This is a much sought after facility, which is not provided by changing the speed of a tape recorder or modifying the rate at which a digital sound file is read by modules such as Music 5"s LUM, and this is but one of the possibilities. The analysis data can, for instance, be used to control the parameters of a sound spectrum which is entirely different from the source material or the amplitude envelope for different partials can be interchanged. In more extreme cases a detected amplitude envelope can be used to control a frequency parameter. Indeed, the instrumental or vocal source sound can be used not so much for its intrinsic spectral character but as a source of control parameters. A frequent criticism of the early computer synthesised pieces is that sounds are too static and lifeless. Experiments which have been conducted by injecting randomness into the control parameters of a signal, so as to simulate chance factors which enliven instrumental performance, have been partially successful. Analysis based synthesis provides a means of extracting those life-like qualities of recorded instrumental performance which are relevant to a particular application. These can then be used as control parameters for computer generated material, which may or may not resemble the sound analysed. The analysis may be performed by the more complex analysis/resynthesis methods or by the simpler envelope and pitch detectors described earlier.
The implementation of pitch and envelope detectors on off-line, or more notably real-time synthesiser, systems means that any musical instrument may be used as a 'peripheral' to control the synthesis process. This offers exciting possibilities for both real time and non-real time working. It is often difficult to express all the nuances of musical phrasing using a language oriented system. The ability to make a synthesis system respond to input material should make it easier to obtain the nuances required. The ease with which this can seemingly be achieved with digital synthesisers may well be the most significant contribution of their introduction, since eventually this should lead to the development of sophisticated systems that can respond musically to other instrumentalists in live performance. These possibilities were already hinted at in "Wellenspiele" for piano, 14 instruments and digital synthesiser by the Swiss composer Balz Trumpy. This was first performed at IRCAM on Friday 13th October 1978, and was realised, with great courage, when the 4C system was barely operational. Of course, the real time systems can also perform the simpler arithmetic operations on sound samples to produce ring modulation and many of the other sound transformations mentioned earlier.
Automated mixing is intrinsic to these systems, and it is the author's belief that the rapid development of digital circuitry will mean that the computer-aided mixdown systems, currently being introduced into multi-track recording studios to enable complicated sequences of fader settings to be precisely synchronised, may well be as short-lived as their counterpart the computer controlled analogue synthesiser. Of course, there are still some problems to be resolved, and perhaps the most significant of these is the storage of the digitised signals. With a sampling rate of 40000 and sample-size of 16 bits, 1 second of a 24-channel recording requires an amazing 960,000 (16-bit) words of disc space (ie : 15.36 million bits) and 30 minutes of music, the duration of a long classical movement which a producer may wish to record in a single take, would need 1728 million words, the capacity of about 12 300-megabyte disc packs.(*) Such an extended file could be replayed using 3 disc transports by reading from one while a second is loaded and a third unloaded, with a changeover every two minutes, but this would be cumbersome to say the least. Moreover, there are limitations to the speed at which disc systems can transfer information and about 1.2 megabytes per second is the fastest which can be achieved using currently available computer systems of a size practical for use in a recording studio. This means that 15 or 16 tracks is the maximum which can be replayed at the same time with the disc system operating flat out. Data reduction techniques, such as Huffman coding, can be used to reduce the number of bits required per sound sample but, unless the coding and decoding is implemented in hardware it is useless for real-time systems, where there may be as little as a microsecond available for all the calculations to be performed on each sample. Disc systems are useful and probably essential as part of the sound processing system because they provide random access to the recorded digital sound samples. Fortunately, most bulk transfer operations can be implemented serially, since the samples are normally required in the same order as they have been recorded, and high-density magnetic tape can be used. The BBC Engineering Research Division have been working on a digital tape recorder, which is similar to the tape transports used on conventional computer systems except that 12 bits can be recorded per frame instead of 6 or 8. This means that only one frame is needed for each sample, thus increasing both the capacity and transfer rate. Some Japanese companies and notably the American 3M group have developed digital recorders using a recording system based on the techniques employed in video tape recorders (VTRs). The 3M system, developed in collaboration with the BBC, has already been delivered to 4 North American studios: LA Record Plant, A&M Records, Warner Bros Records and Studio 80.
An important question to be resolved in designing digital recording systems is that of automatic error correction. Just as analogue systems suffer from tape 'drop-outs', etc., the sheer volume of information to be recorded means that there are likely to be a few errors in the digitally stored samples. Fortunately, digital techniques enable us to correct these either by identifying and replacing the incorrect sample with one extracted from a duplicate recording or interpolating between adjacent sample values in a channel. When high enough sampling rates are used, an individual sample may be only one of many representing a more or less constantly varying portion of a sound wave. In such circumstances replacing an incorrectly recorded sample with a value half-way between its neighbours is unlikely to produce any audible distortion. When matters such as these are more fully researched and digital circuitry becomes even cheaper, digital systems should rapidly replace their analogue counterparts. The accuracy with which sound instants can be located and the precision and variety of the transformation processes which can be applied to the digitised sound should be attractive to recording studios, where an appreciable amount of time can still be lost working with analogue tape recording techniques. Moreover, for sound archiving purposes digital recording provides enormous advantages since it is not subject to the problems of print through and the gradual deterioration, which affects analogue tapes.
Analysis/resynthesis techniques offer the possibility of extracting intermediate data from sounds, which can then be used to control the parameters of the resynthesis process. This permits even more complex sound transformations to be created and allows greater independence of sound parameters. An obvious application is the changing of the frequency of a sound without modifying its duration. Pitch and envelope followers implemented either in real time or non real time systems can be used to extract parameters from live instrumental performance to enliven synthesised sounds. This could have a great impact on computer music, helping composers avoid the more obviously mechanical applications and use the computer or digital synthesiser for their wealth of sound transformation possibilities.
(*) DUR as frequency control for an oscillator specifies
1 cycle per note)
(*) Disc sizes are usually given in bytes, of which there are 2 per word
Appendix 1 : Music 5 Pass 3 Fortran Subroutine for the Sound
Detector
SUBROUTINE PLT(it)
COMMON I(1)
COMMON /PARM/ CONTRL(50), IP(75), PFNBR, P(100)
C
REAL*4 IE(1)
EQUIVALENCE (IE(1), I(1))
EQUIVALENCE (ITSAMP, IP(46))
COMMON /LM/ NPW, INSLOC, NGEN, IDXSAM, INSAM
COMMON /STRCTL/ MAXVAR(7), FPLACE(75), INSDEF(100), BPLACE(100),
1 NOTLOC, ENDLOC
INTEGER*4 PLACE, ENDLOC, BPLACE
real durcli(30), debcli, mean
data offdeb/-1/, offin/-1/, nnote/0/, n/1/
lf(offdeb.gt-0) go to 50
open (unit = 1, device = 'TTY', access = 'SEQIN', mode = 'ASCII')
1 type 2
2 format (' Offset begin time? '$)
read (1,*,err=20) offdeb
if(offdeb.lt.0) go to 21
10 type 11
11 format (' Offset and time? '$)
read (1,*,err=25) offin
15 type 16
16 format (' Number of clicks? '$)
read (1,*,err=30) nclick
if (nclick.lt.0) go to 31
close (unit 1)
open (unit 1, device = 'DSKB', file = 'TEMPS.DAT',
1 access = 'seqout', mode = 'ASCII')
go to 50
20 read (1,35) offdeb
21 type 23
23 format (' ??')
go to 1
25 read (1,35) offin
type 23
go to 10
30 read (1,35) nclick
31 type 23
go to 15
35 format (a5)
50 itt = it / 2 ** 18 + 0.49
if(itt.ne.1) go to 100
if (i(maxvar(4)).ne.0) return
i(maxvar(4)) = 1
ix = itsamp + idxsam - offdeb
x = ix / contrl(4)
if(n.gt.nclick) go to 70
durcli(n) = x
if(n.eq.1) debcli = x
return
70 debnot = x
nnote = nnote + 1
return
100 if(itt.ne.2) go to 200
if (i(maxvar(4)+1).ne.0) return
i(maxvar (4)+1) = 1
ix = itsamp + dxsam - offin
x = ix / contrl(4)
if(n.gt.nclick) go to 150
y = x - durcli(n)
type 120,y, durcli(n)
120 format (' Duration of click = ', f8.4, ' at time ', f8.4)
n = n + 1
if(n.le.nclick) return
nn=nclick-1
mean=0
do 130 ii=1,nn
130 mean = mean + durcli(ii+1) - durcli(ii)
mean = mean / (nclick-1)
st = durcli(nclick) + mean/2
type 135, st
135 format (' Theoretical starting time: ', f8.4)
write (1,140) st
140 format (1x,f8.4)
return
150 write (1,160) debnot,x
160 format (1x,f8.4,1x,f8.4)
type 170,debnot,x
170 format (' Note begining at ', f8.4, ' ending at ', f8.4)
return
200 ix = itsamp + idxsam - 1
x = ix / contrl(4)
type 220,x,nnote
220 format (' End of file at time: ', fB.4,/,' Number of notes = ',
1 i10)
close (unit = 1)
return
end
Appendix 2 : PLF Subroutine for use in Pass 1
SUBROUTINE PLF
C
C SUBROUTINE TO EXTRACT TIMINGS FROM FILE "TEMPS.DAT" FOR THE
C PROCESSING OF YORK HOLLER's "ARCUS" (AUGUST 1978)
C STANLEY HAYNES
C
C VARIABLES AND ARRAYS:
C CODE(40) holds the frequencies of the code In hertz
C IP5 (1 or 2) indicates how many P fields are to be created
C NOTES shows the number of notes to be created
C INCR is the Increment for the pointer to CODE
C ICNT1 Is the pointer to CODE for the 1st P field
C NR1 is the number of the parameter for 1st P field to
C obtain a value from the CODE
C RATIO1 is the frequency ratio for the 1st P field
C FACT1 is the expansion/contraction factor (normally 1.0)
C ICNT2, NR2 FACT2 & RAT102 correspond where relevant to the
C above for the 2nd P field
C TZERO is theoretical start time in secs of input sound file
C THE SET VARIABLES - D(199) IS THE NUMBER OF P's (NOT catd)
C D(200) is an adjustment in secs to the attack time
C D(201) is an adjustment in secs to the end time
C D(197) is the Increment scanning CODE for the 1st P field
C D(198) is the increment scanning CODE for the 2st P field
C
C
COMMON /PARM/CONTRL(50), IP(75), PFNBR, P(1)
INTEGER PFNBR
DIMENSION CODE(40)
COMMON /DG/D(1)
EQUIVALENCE (SAM,CONTRL(4))
EQUIVALENCE (XNFUN,CONTRL(46))
EQUIVALENCE (CODE1,CODE(1))
REAL*8 DDNAME
DATA (CODE(I), I=1,40)/293.7, 311.1, 293.7, 349.2, 277.2, 329.6
&,293.7, 349.2, 370, 311.1, 277.2, 392, 415.3, 392, 293.7, 311.1
&,415.3, 440, 349.2, 329.6, 370, 311.1, 392, 277.2, 293.7, 440
&,329.6, 466.2, 415.3, 349.2, 370, 493.9, 466.2, 392, 440, 329.6
&,311.1, 277.2, 261.6, 293.7 /
C
C SET FILE NAME FOR INPUT TIME PARAMETERS
C
IF (DDNAME .NE. 0.0) GO TO 5
TYPE 1
1 FORMAT(' GIVE FILENAME FOR NOTE TIMES DATA '$) !usually "TEMPS.DAT"
ACCEPT 2,DDNAME
2 FORMAT (A10)
OPEN(UNIT=2,DEVICE='DSK',ACCESS='SEQIN',FILE=DDNAME,MODE='ASCII')
C READ IN TIME IN I/P FILE CORRESPONDING TO ZERO IN O/P FILE
READ (2,200) TZERO
200 FORMAT (F8.4)
TZERO = TZERO - 1 ! 1 "SILENCE ADDED AT BEGINNING OF FILE
C
5 IP5 = P(5)
INSNR = P(4)
IF (IP5 .NE. 2) GO TO 10
ICNT2 = P(10)
NR2 = P(9)
RATI02 = P(11)/CODE1
IF (P (3) .EQ. 0. 0) P (3) = 1. 0
C FACT2 (P(3)-CODE1)/200.2 ! 200.2 IS GREATEST-1ST OF CODE
FACT2 = P(3)
INCR2 = D(198)
IF (INCR2 .EQ. 0) INCR2 = 1
10 ICNT1 = P(7)
NR1 = P(6)
RATIO1 = P(8)/CODE1
IF (P(2) .EQ. 0.0) P(2) = 1.0
C FACT1 = (P(2)-CODE1)/200.2
FACT1 = P(2)
INCR1 = D(197)
IF (INCR1 .EQ. 0) INCR1 = 1
C
C LOOP TO PRODUCE NOTE CARDS
C
20 READ(2,201,END=1000) AT, FT
201 FORMAT (F8.4,1X,F8.4)
AT = AT + D(200)
FT = FT + D(201)
P(2) = AT - TZERO
P(4) = FT - AT
P(5) = AT ! START TIME FOR "LUM" IN I/P FILE
P(NR1) = RATIO1 * (CODE1 + (CODE(ICNT1)-CODE1) * FACT1)
ICNT1 = ICNT1 + INCR1
IF (ICNT1 .GT. 40) ICNT1 = ICNT1 - 40
IF (ICNT1 .LT. 1) ICNT1 = ICNTI + 40
IF (IP5 .NE. 2) GO TO 30
P(NR2) = RATIO2 * (CODE1 + (CODE(ICNT2)-CODE1) * FACT2)
ICNT2 = ICNT2 + INCR2
IF (ICNT2 .GT. 40) ICNT2 = ICNT2 - 40
IF (ICNT2 .LT. 1) ICNT2 = ICNT2 + 40
C
C WRITE NOTE CARDS
C
30 P(1) = 1.0
P(3) = INSNR
C
C P(7) = D(196)*P(8) - P(8)
PFNBR = D(199)
CALL WRITE
GO TO 20
C
1000 CLOSE (UNIT=2)
RETURN
END
Appendix 3 : Syntax of Statement to Call PLF Routine & its Control
Paramaters
The PLF routine listed in Appendix 2 is brought into play by a statement of
the following type placed in the Music 5 score determining the sound
transformation where the NOTE statements would normally appear ;
PLF rng1 rng2 insnr Pnr nrl indl trspl nr2 ind2 trsp2;
means that the 6th parameter of the NOTE statements will be assigned consecutive values beginning with the 3rd element of the series transposed such that its first element is 293.7 Hz, and the 8th parameter will begin with the first element of the series transposed to 440 Hz. In the latter case, the transposed series is expanded to cover 2 octaves.
eg: PLF 1 2 1 2 6 3 293.7 8 1 440;
The more rarely used facilities are controlled using Pass 1"D" variables set with "SV1" statements :
____________________________
Server © IRCAM-CGP, 1996-2008 - file updated on .
____________________________
Serveur © IRCAM-CGP, 1996-2008 - document mis à jour le .