
Tous droits réservés pour tous pays. All rights reserved.
| Serveur © IRCAM - CENTRE POMPIDOU 1996-2005. Tous droits réservés pour tous pays. All rights reserved. |
Journal of the Acoustical Society of America, 1991
Copyright © ASA 1991
b)Requests for reprints should be addressed to S. McAdams at the Laboratoire de Psychologie Expérimentale.
Sub-audio frequency modulation, applied to the components of a sound in such a way as to maintain the frequency ratios among them ("coherent" modulation), has been shown to contribute to the ability of a listener to segregate perceptually the sound from a background (Chowning, 1980; McAdams, 1984a,b, 1989; Chalikia and Bregman, 1989). In McAdams (1989), three vowels at fundamental frequencies (F0) separated by five semitones were presented simultaneously to listeners. Several modulation configurations were used: 1) no vowels modulated, 2) a single vowel modulated and two vowels steady, 3) a single vowel modulated against a background of two coherently modulated vowels, and 4) all three vowels modulated coherently. Subjects were asked to rate the perceived prominence of each vowel in the mixture. It was assumed that if the components of a vowel were not grouped by the ear, subjects would not be able to perceive the target vowel easily and would thus give it a low prominence rating. If, on the other hand, the vowel was clearly distinguished from the other background sounds, subjects would easily perceive it and rate its prominence higher. The hypothesis was that a vowel modulated independently of other vowels would be more easily separated and thus receive higher prominence ratings than when it was not modulated or was modulated coherently with other vowels. The results showed that a vowel that was modulated was judged to be more prominent than a vowel that was not modulated. However, this increase in prominence was independent of whether the vowel was modulated independently of, or coherently with, other vowels. Thus, while modulation of a harmonic sound increased its perceived prominence, the coherence of modulation on vowels at different F0's separated by a ratio of 1.33 had no effect.
Huggins (1952, 1953) has suggested that the auditory system encodes aspects of the structure of a physical source. In the case of resonant sources, one aspect of this structure would be closely related to the spectral envelope. There is, in addition, an important possible interaction between frequency modulation and resonance structure in the perception of sound sources. Formant placement for a given vowel changes systematically across pitch registers in singing and formant relations evolve in ongoing speech. However, the spectral envelope tends to change relatively slowly with respect to the rate of frequency change of jitter or vibrato on the fundamental. With frequency modulation, each modulated component traces the spectral envelope of the vowel to which it belongs, thus possibly providing additional information about the resonance structure embedded in a multi-source complex. The coupling between amplitude modulation and frequency modulation as a function of the resonance structure may help define the spectral envelope (by "tracing" the envelope) and thus help with its identification (McAdams, 1984a). Vibrato-induced spectral envelope tracing has been shown to facilitate the discrimination and identification of resonance structures (McAdams and Rodet, 1988). Spectral tracing is a feature of the formant-wave-function synthesis algorithm (Rodet, 1980) used in McAdams (1989), who hypothesized that this property of a resonance structure may help the auditory system identify the vowel and consequently result in an increase in its judged prominence.
It seems logical then that fixed resonance structure (as encoded through spectral envelope tracing) might be a cue for grouping. Features of the spectral envelope are certainly a crucial part of the information from which vowel identity is derived. Vowel prominence judgments are most likely closely tied to the ability of a listener to extract a spectral envelope from the complex spectrum and identify it as such. Factors that may impede this extraction would include: 1) the lack of definition of the spectral envelope by the frequency components composing the vowel, as is the case, for example, with a higher F0, 2) the inability to extract the spectral envelope when the components that define it are grouped with other components, which thus give rise to a different spectral envelope , or 3) the masking of features essential for vowel recognition and identification, such as the lower two or three formant peaks (Carlson, Fant and Granström, 1975; Karnickaya, Mushnikov, Slepokurova and Zhukov, 1975).
With the synthesis algorithm used by McAdams (1989), each group of components representing a vowel was modulated under a constant spectral envelope, i.e. the resonance structure was unchanging. With no modulation, the nature of the resonance structure may have been ambiguous depending on the number of partials contained in each formant band. As modulation was added, each partial's frequency-amplitude motion potentially provided information about the slope of the spectral envelope in that region. When these components were taken as an ensemble, this slope information may have greatly reduced the ambiguity of identity. We would expect a reduction in ambiguity to be accompanied by an increase in prominence judgments.
This hypothesis was supported in the 1989 data by the large increase in prominence with modulation for the highest pitch of each vowel. With no modulation and a higher fundamental, there were fewer components within the formant pass-bands and the spectral form was thus less well defined. With modulation, this structure would be more clearly defined by the coupled frequency-amplitude motions. For adjacent partials belonging to separate vowels, these motions might be incompatible and indicate separate formant structures. In essence, each sub-group of partials traced its own spectral envelope. But this increased definition would only be possible if the auditory system could succeed in extracting the envelope information from the unresolved adjacent partials. Such would need to be the case for the relatively dense spectra employed in that experiment. The extent to which these envelopes could then be separated would influence the judged prominence of each of them.
The possible role of spectral envelope tracing in the presence of frequency modulation on vowel spectra was tested in the following experiment. Chords of three vowels in various pitch permutations were used as in the 1989 study. In addition, two conditions were used: one in which the amplitudes of the spectral components varied as a function of the vowel spectral envelope, and on in which they remained at the amplitudes assigned to the components in steady state vowels. These two cases are illustrated in Figure 1. Our hypothesis is that in addition to the positive effect of frequency modulation on judged vowel prominence, we should see greater prominence judgments for stimuli in which the spectral envelope is traced compared to those for which it is not traced. Note that in the latter case, the spectral envelope as a whole is modulated in frequency.
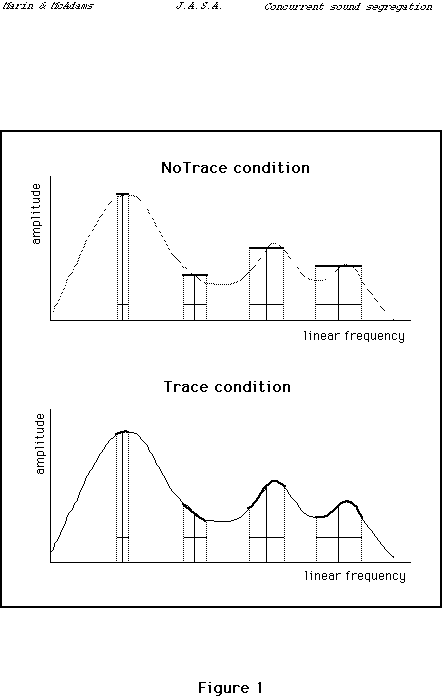
FIG. 1. Illustration of two kinds of vowel synthesis. Amplitudes of frequency
components are initially chosen according to a spectral envelope for each
vowel. In the NoTrace condition, these amplitudes remain constant
as the frequencies are modulated. In the Trace condition, the
amplitudes modulate with the frequency according to the spectral envelope.
To analyze the role of the spectral envelope tracing by the harmonics of a vibrato vowel, two blocks of stimuli were prepared (see Fig. 1). The first block (NoTrace) was composed of vowels in which the amplitudes of the harmonic components remained constant when modulated in frequency. They did not trace the spectral envelope of the vowel. The second block (Trace)was composed of vowels with harmonics which traced the spectral envelope of the vowel when modulated.
The vowels used in McAdams' (1989) experiment had been synthesized with a formant-wave-function synthesis algorithm (Rodet, 1980). The latter method does not permit independent behavior of amplitude and frequency of harmonics when the frequency is modulated. Therefore, the vowels in the present study were synthesized via an additive (Fourier) synthesis algorithm on an FPS-100 array processor connected to a VAX 11/780 computer. The center frequencies, bandwidths, and relative levels of the formants of the different vowels are listed in Table I. The spectral envelope functions derived from these parameters were stored in a table. To synthesize the vowels in the Trace block, the instantaneous value of the amplitude was given as a function of instantaneous frequency, according to the function in the table, for each harmonic at each sample. For the vowels in the NoTrace block, the amplitude value of each harmonic was determined beforehand according to the function table. Each harmonic then kept this amplitude value for the entire steady-state duration of the vowel.
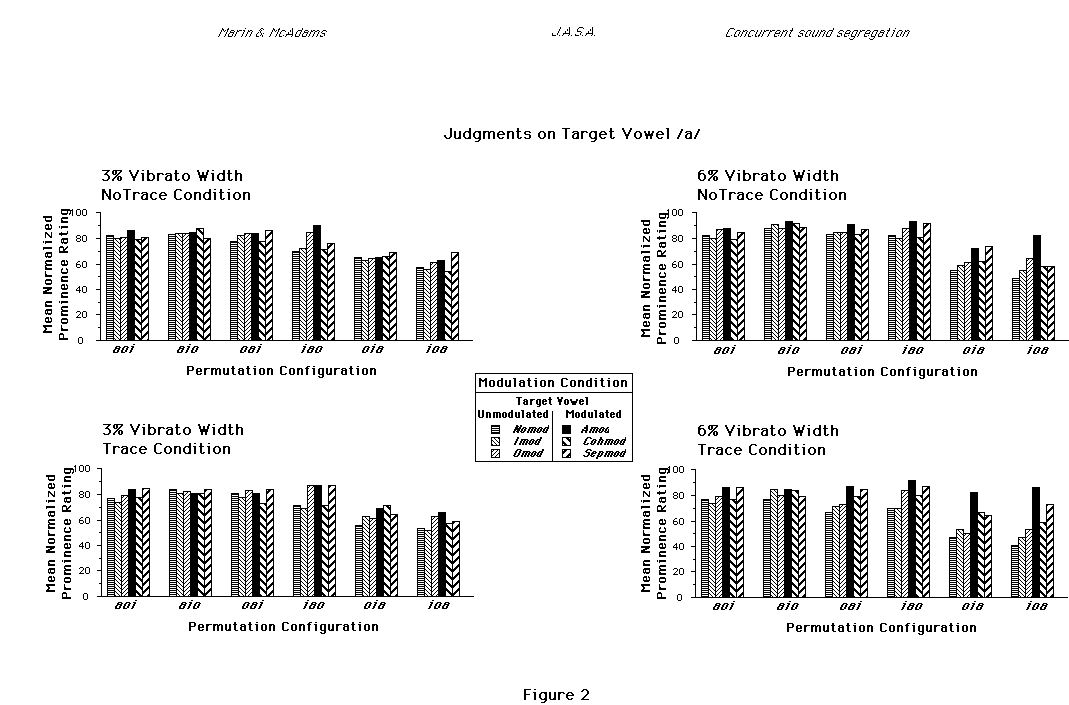
FIG. 2. Mean normalized prominence ratings on vowel /a/ across ten subjects
within each of the vibrato width conditions. Vibrato width X Tracing conditions
are shown in separate plots. Modulation conditions are grouped by Permutation
configuration. Permutation configurations are arranged from left to right in
order of increasing F0 of the target vowel. Modulation conditions are arranged
with target unmodulated conditions to the left, and target modulated conditions
to the right within each Permutation configuration.
Loudness matching was performed by six subjects on each vowel in isolation, at all pitches, with and without vibrato in both tracing and non-tracing conditions. The vibrato had a rate of 5.1 Hz and a width of 3%. Each condition was judged at least two times by each subject.1 The means of these judgments were used to equalize the loudnesses of individual vowel stimuli before mixing them into chords. There was no effect of envelope tracing and vibrato presence and very little effect of pitch on loudness matches. Vowels /a/ and /i/ tended to be adjusted on the order of 3 dB below the rms level of /o/ vowels.
As in the McAdams (1989) study, each experimental stimulus consisted of a chord composed of one each of the three vowels /a/, /i/, and /o/ at the three fundamental frequencies. Permuting the pitch positions of the three vowels gives six chords which are each notated in order of increasing F0 of the vowels: aoi, aio, oai, oia, iao, ioa.
For each permutation, six different modulation conditions were used : Nomod -- no vowel was modulated; Amod -- vowel /a/ was modulated alone at a rate of 5.1 Hz, while the other two vowels remained unmodulated; Imod -- vowel /i/ was modulated alone at 5.1 Hz; Omod -- vowel /o/ was modulated alone at 5.1 Hz; Cohmod -- all three vowels were modulated coherently at 5.1 Hz; Sepmod -- all three vowels were separately modulated at different vibrato rates (5.1, 5.7, 6.3 Hz). In the latter condition, the vibrato rates were randomly assigned to each vowel within different permutation and tracing combinations.
To obtain the different permutation and modulation combinations for each level of the tracing and vibrato width conditions, individually synthesized vowels were combined by a digital mixing program (in 32-bit format) to form the chords and stored in 16-bit format. These stimuli were then transferred to a PDP 11/34 minicomputer and presented through Tim Orr 16-bit DACS and a 6.4 kHz, -96 dB/oct, low-pass filter to Beyer DT-48 headphones. They were presented diotically at a level of approximately 75 dBA as measured at the earphones with a flat-plate coupler connected to a Bruel & Kjaer 2209 sound level meter.
Twenty subjects participated in the main experiment. Ten subjects were presented stimuli with a peak-peak vibrato width of 3% and ten others received the 6% vibrato width stimuli. The main experiment was divided into two sessions with the Trace and NoTrace conditions presented in separate sessions on different days. The order of the two conditions was evenly divided between the subjects within each of the 3% and 6% groups. Stimuli consisted of 6 permutations X 6 modulation conditions X 5 repetitions for each session. These 180 stimuli were presented in block randomized order with each stimulus being heard before a repetition was presented.
Subjects were informed that they were to judge the perceptual prominence of the vowels /a/, /i/ and /o/ within a complex stimulus. A slider provided for entering the judgments was labeled "very prominent" at the top and "not at all prominent" at the bottom. The experimenter indicated to the subjects that if the vowel was very clear or prominent and they were certain of its presence, then the slider was to be positioned at the top. If it was clearly not present, the slider was to be positioned at the bottom. If the impression of prominence or presence was in between, the slider was to be positioned accordingly. This demonstration should have induced the subjects to use the slider according to a linear scale of prominence. Subjects were told prior to the experiment that the three vowels might not necessarily be present in each stimulus. On each trial subjects heard a 2-sec complex sound repeated twice with an interval of 1 sec between the two sounds. They were to judge the prominence of the vowel /a/ and position the slider. Then upon pressing a button, the same sound was heard twice a second time, after which they were to judge the prominence of the vowel /o/. Following this judgment a third presentation was provided for a judgment of the prominence of the vowel /i/. At each presentation, the target vowel to be judged was indicated on the screen of a computer terminal. Upon pressing the button for each judgment, the slider position was recorded and coded with a value between 0 (not at all prominent) and 100 (very prominent). At the end of three such judgments, the experimental program proceeded to the next stimulus configuration. Two breaks were introduced during each session, which made for three periods of roughly 25 to 30 minutes each.
In each session, a trial sequence was presented during which the subject was to rate the presence of each vowel in the six modulation conditions of one permutation configuration, according to the tracing block being tested. The trial sequence was repeated if either subject or experimenter felt that the task had not been understood.
In summary, two groups of ten subjects each received either the 3% or 6% vibrato width. Within each group, all subjects received the Trace and NoTrace conditions in two separate sessions. Within each session, 180 stimuli were presented comprising six permutations each in six modulation configurations, with each such combination being repeated five times.
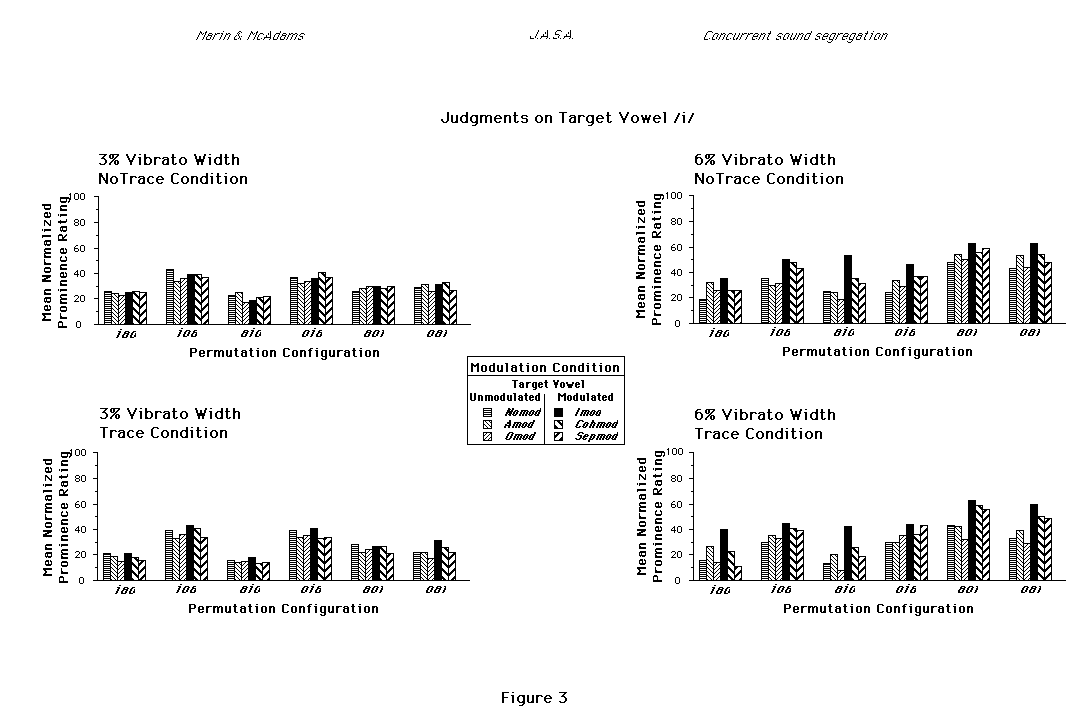
FIG. 3. Mean normalized prominence ratings on vowel /i/ as in Fig. 2.
The mean normalized prominence ratings for each target vowel were submitted to independent four-way analyses of variance: subjects (10) within vibrato width (2) X tracing (2) X permutation (6) X modulation condition (6).
For modulation contrasts, we were interested in differences 1) among modulation conditions where the target vowel was not modulated (e.g. among Nomod, Imod, Omod for /a/) and 2) among modulation conditions where the target vowel was modulated (e.g. among Amod, Cohmod, Sepmod for /a/). In general, comparisons among unmodulated target vowel conditions were not statistically significant, indicating that the modulation state of non-target vowels did not affect prominence judgments. The results of two groups of orthogonal contrasts on conditions in which the target was modulated are summarized in Table III. Comparisons among modulated target vowel conditions depended strongly on vibrato width. Only two comparisons were significant at the 3% vibrato width for /a/. At the 6% vibrato width, the comparisons between vowel modulated alone and either Cohmod or Sepmod conditions were highly significant for all three vowels. The Cohmod-Sepmod comparison was not significant. These results indicate that the greatest prominence is attained when the target vowel is modulated alone, compared to when it is modulated at the same time as the other vowels, whether this modulation be coherent or not. They also confirm McAdams' (1989) finding that the coherence of modulation among vowels has no effect on prominence ratings.
These comparisons suggest that the data for conditions where the target vowel is not modulated can be regrouped (into Unmod), as can conditions where all three vowels are modulated (into Allmod). The second group of contrasts (see Table IIIb) compares these two regrouped conditions with the one in which the target vowel is modulated alone (Vmod). Here, the difference in the pattern of results at 3% and 6% vibrato widths is also strongly apparent as can be seen in the presentation of regrouped data in Figure 5. Comparisons are rarely significant at the 3% width. Only the Unmod-Vmod comparison just attains the criterion significance level for the vowel /a/. All comparisons at the 6% vibrato width are highly significant for all three vowels. The ordering of the means are always Unmod < Allmod < Vmod. Taken together, these results support those of McAdams (1989) which demonstrated that the presence of a certain amount of frequency modulation on a vowel embedded among other vowels increases its perceptual prominence. In the present experiment, this effect is strongest if the target vowel is the only one modulated. Concurrent modulation of the other vowels reduces the target vowel's prominence, though with a 6% vibrato width this prominence is still greater than when the vowel is not at all modulated.
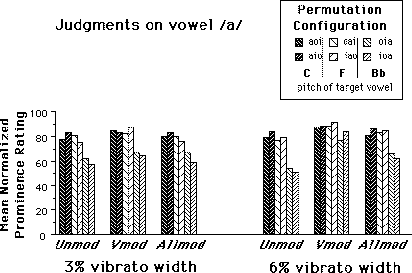
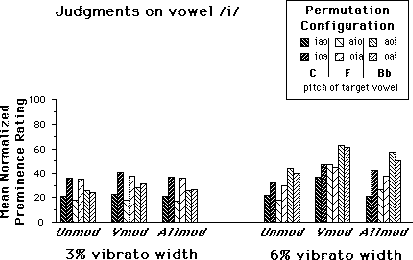
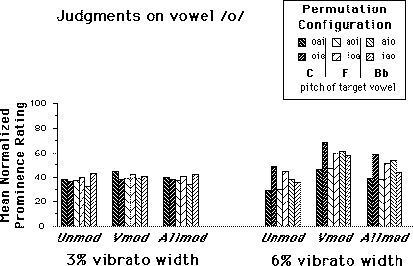
FIG. 5. Mean normalized prominence ratings across ten subjects within each Vibrato width condition and across Tracing conditions for judgments on vowels /a/, /i/, and /o/. The six original Modulation conditions have been collapsed according to the modulation states of the component vowels (see text). Permutation configurations are grouped according to Modulation condition and are arranged from left to right in order of increasing F0 of the target vowel.
One might ask whether the amount of amplitude modulation induced by vibrato under the vowel spectral envelopes was large enough to be useful to listeners. We computed the AM depth induced by a 6% vibrato on harmonics within each formant for all vowels at the three F0's used. Only harmonics that were within 10 dB of the formant peak were analyzed. For all vowels at all pitches, at least one and as many as three harmonics satisfied the criterion in each formant. The only exception was /o/ at the highest pitch where the first two harmonics straddled the F1 peak and had levels of -17 and -15 dB re peak, respectively. For all other cases the induced AM varied between 1.3 and 13.3 dB, values generally above AM detection threshold. The average induced AM present on harmonics forming each formant (across vowels and pitches) was 2.7 dB for F1 (range 1.5 - 4.6), 4.9 dB for F2 (range 1.7 - 8.4), 6.7 dB for F3 (range 3.2 - 10.3), 8.3 dB for F4 (range 3.2 - 13.3), and 7.1 dB for F5 (range 1.3 - 13.0). The negative result concerning the contribution of spectral envelope tracing to sound source separation cannot thus be discounted on the basis of insufficient AM on the harmonics.
It remains possible, following the earlier-mentioned suggestions of Huggins (1952, 1953), that isolating a single, analytic aspect of resonance behavior such as spectral envelope tracing, does not capture a behavior to which the auditory system is sensitive. It does not seem far-fetched to suppose that this system has been attuned by the process of evolution to the complex behavior of physical resonators which are so ubiquitous in the sound environment. When envelope tracing is not accompanied by, for example, an appropriate phase modulation in the region of the formant center frequency, the auditory system, if it were biased toward the analysis of resonant structures, might not recognize such behavior as "meaningful". Such speculation remains to be verified experimentally.
Several effects due to the modulation states of concurrent vowels were revealed at the 6% vibrato width. Modulation of a non-target vowel had no impact on prominence ratings of unmodulated target vowels either at 3% or 6% modulation. When all three vowels were modulated, there was no effect on prominence ratings of their being modulated coherently or independently. This same tendency was found by Chalikia and Bregman (1989) who presented subjects pairs of vowels for which the F0's were steady, gliding in parallel or gliding such that the contours crossed one another midway through the stimulus duration. In addition, the maximum F0 separation between vowels varied from 0 to 12 semitones. They found that while there was a tendency for parallel glides (equivalent to our coherent modulation) to give lower vowel identification scores than crossing glides (similar to our independent modulation condition), the differences were not significant at F0 separations of 1/2, 3 and 6 semitones. The latter value is roughly equivalent to our 5 semitone F0 separation. However, there was a significant decrease in identification scores for parallel glides when the F0 separation was one octave, i.e. a perfectly harmonic relation existed between the components of both vowels. No such decrease was found for crossing glides. This would lead one to suppose that coherent modulation in and of itself is not sufficient to make two harmonic series fuse together. Coherent modulation may increase the fusion of harmonically related components, but not inharmonically related ones. Thus, harmonicity may be considered a constraining factor on the grouping power of coherent modulation. Harmonicity has little or no effect on perceptual fusion due to coherent amplitude modulation (Bregman et al., 1990). In the stimuli in our study, the components of individual vowels can be fused since they are harmonically related, but the groups of components across coherently modulated vowels cannot be fused since they are not harmonically related.
A result in the present study not found in McAdams (1989) was an increase in ratings for a vowel modulated alone compared to when it was modulated in the presence of other modulating vowels (Vmod vs Allmod in Fig. 5). This implies a reduction in prominence due to a mutual interference of multiple modulating sources that perhaps perturbs, without completely obscuring, the information (most likely of a temporal nature) needed by the auditory system to separate and identify the individual sources. While the frequency components were relatively non-coincident due the separation of the three fundamental frequencies by a musical fourth, there was significant overlap of activity patterns on the basilar membrane in the higher harmonics of all three vowels.
There were two differences in the synthesis of the stimuli and one methodological difference between the two experiments. The 1989 study used a time-domain formant-wave-function (FOF) synthesis algorithm whose behavior is closer to (though not identical to) that of a true resonator than the additive synthesis algorithm used here. This difference may implicate a sensitivity in the auditory system to the phase structure of resonators. The other synthesis difference was the use of jitter (1.6% rms modulation width) combined with a sinusoidal vibrato (3% peak-to-peak width) in the earlier study. Only the vibrato was used in the present study. While the presence of jitter may have increased the effective modulation width to some extent, it seems unlikely, given the size of the effects reported in both studies, that such a difference could be entirely responsible for the discrepancies in results.
The methodological difference lay in the amount of time each subject had to listen to each stimulus configuration. In the 1989 study, subjects listened continuously to the repeating 2-sec stimulus while making the prominence ratings for the three vowels in succession. Some subjects may have listened to a given stimulus for as long as 30 to 60 secs (10 - 20 presentations). In the present study, each stimulus was presented twice for each vowel judgment, or a total of 6 times per repetition. The kind of listening strategy developed may have been quite different in the two cases, and a prolonged presentation of the stimulus could allow the listener more time to focus on cues related to frequency modulation.
APPENDIX : Discriminability of Multiple Vibrato Rates In order to facilitate the interpretation of the effects of frequency modulation coherence on vowel prominence ratings, it was necessary to establish that the presence of single or multiple vibrato rates could be distinguished. This is particularly important for the comparison between CohMod and SepMod conditions. If these could not be discriminated, one would not expect prominence judgments to be different between them.
A.1 STIMULI Stimuli were constructed from pairs of 16-component, flat-spectrum harmonic series based on the three F0's used in the main experiment (130.8, 174.6, 233.1 Hz). This yielded three possible F0 pairs. Each harmonic series was modulated with a 3% peak-to-peak sinusoidal frequency modulation. Tones were 2 sec in duration with 200 msec raised cosine attack and decay ramps. The stimuli were synthesized at a sampling rate of 16 kHz. The sound presentation system was identical to that in the main study. Each trial consisted of 2 tones separated by a 500 msec silence. In the standard tone, the vibrato rates on both sets of harmonics were identical. In the comparison tone, a different vibrato rate was present on either the higher or the lower harmonic series. The 5.1 Hz rate was compared with both 5.7 and 6.3 Hz rates (rate differences of 0.6 and 1.2 Hz, respectively). The order of standard and comparison tones was randomized. Subjects were asked to decide which of two tones in a trial had a single vibrato rate present on both harmonic series. In essence, they were to detect the tone which had coherent frequency modulation. Performance was measured as the percentage of correct responses. Each configuration of vibrato comparison and pitch pair (24 total) was repeated 5 times in block randomized order (120 trials per session). Eight subjects (including the authors) each completed two sessions. Only data from the second session were analyzed.
A.2 RESULTS The results are summarized in Table A.I. The data were submitted to an analysis of variance with Pitch pair and Vibrato rate pair as factors (3 X 2). There was no effect of Vibrato rate nor was the interaction term significant. Thus the 0.6 and 1.2 Hz differences in vibrato rates are equally distinguishable within each pitch pair. There was, however, a significant effect of Pitch pair (F(2,186) = 156.8, p<.0001): performance is close to perfect when the pitch separation is 5 semitones and falls almost to chance when the separation is 10 semitones. In essence, the latter condition is not relevant to our study since adjacent vowels were always separated by 5 semitones. This auxiliary study thus rules out the possibility that the lack of difference in prominence judgments between CohMod and SepMod conditions was due to listeners' inability to discriminate between them.
[ insert Table A.I about here ]
FOOTNOTES
1Two subjects made two judgments for each condition; three subjects made six judgments and one subject made seven judgments. There were no significant differences among these three groups.
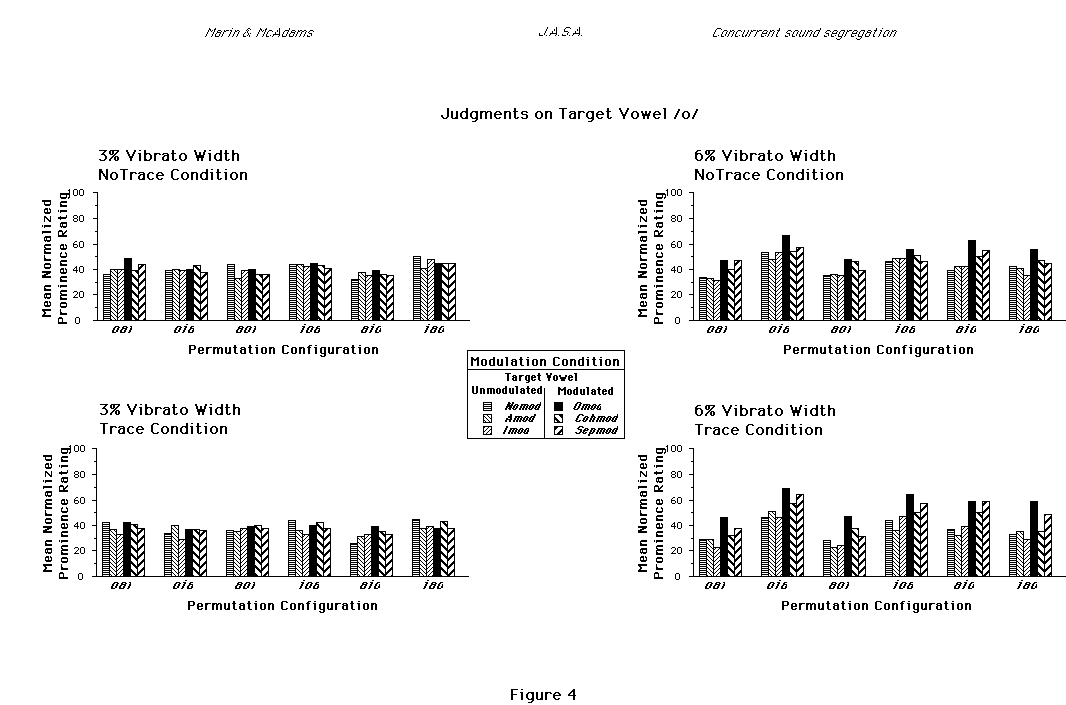
2Figs. 2-4 show that, across conditions, /a/ was judged as more prominent than /o/ which was judged more prominent than /i/. The same qualitative result was found in McAdams (1989) and was attributed in that paper to masking effects among vowels (section II.C.6, p. 2155).
3Significant interactions of secondary interest to this study which are not discussed in the text include the following: Modulation X Tracing for /a/ (F(5,90) = 6.60, p < .001); Modulation X Vibrato width X Tracing for /a/ (F(5,90) = 3.16, p < .05); Permutation X Modulation X Tracing for /a/ (F(25,450) = 2.07, p < .01); Permutation X Tracing for /i/ (F(5,90) = 2.70, p < .05).
4Seven of the 18 contrasts performed on permutations within target vowel pitch positions were statistically significant (e.g. between aoi and aio for /a/). The prominence relations of target vowels at different pitches qualitatively reflect the same structure found in the 1989 study for vowels /a/ and /i/. Due to the differences within pitch position, however, we cannot conclude that the principal effect of permutation is due to pitch position of the target vowel, as was the case in that earlier study.
REFERENCES
Bregman, A.S., Levitan, R., and Liao, C. (1990) "Fusion of auditory components: Effects of the frequency of amplitude modulation," Percept. & Psychophys., 47, 68-73.
Carlson, R., Fant, G., and Granström, B. (1975) "Two-formant models, pitch and vowel perception," in Auditory Analysis and Speech Perception, edited by G. Fant and M.A.A. Tatham (Academic, London), pp. 55-82.
Chalikia, M., and Bregman, A.S. (1989) "The perceptual segregation of simultaneous auditory signals: Pulse train segregation and vowel segregation," Percept. & Psychophys., 46, 487-496.
Chowning, J. (1980) "Computer synthesis of the singing voice," in Sound Generation in Winds, Strings, Computers (Royal Swedish Academy of Music, Stockholm), publ. no. 29.
Huggins, W.H. (1952) "A phase principle for complex frequency analysis and its implications in auditory theory," J. Acoust. Soc. Am. 24, 582-589.
Huggins, W.H. (1953) "A theory of hearing," in Communication Theory, edited by W. Jackson (Butterworths, London), pp. 303-379.
Karnickaya, E.G., Mushnikov, V.N., Slopokurova, N.A., and Zhukov, S.J. (1975) "Auditory processing of steady state vowels", in Auditory Analysis and Speech Perception, edited by G. Fant and M.A.A. Tatham (Academic, London), pp. 37-53.
Marin, C.M.H. (1987) Rôle de l'enveloppe spectrale dans la perception des sources sonores, DEA thesis (Université Paris III, Paris).
McAdams, S. (1984a) "The auditory image: A metaphor for musical and psychological research on auditory organization," in Cognitive Processes in the Perception of Art, edited by R. Crozier & A. Chapman (North-Holland, Amsterdam), pp. 298-324.
McAdams, S. (1984b) "Spectral fusion, spectral parsing and the formation of auditory images," unpublished PhD. dissertation (Stanford University, Stanford, CA).
McAdams, S. (1989) "Concurrent sound segregation. I: Effects of frequency modulation coherence," J. Acoust. Soc. Am. 86, 2148-2159.
McAdams, S., and Rodet, X. (1988) "The role of FM-induced AM in dynamic spectral profile analysis," in Basic Issues in Hearing, edited by H. Duifhuis, J.W. Horst, and H.P. Wit (Academic, London), pp. 359-369.
Rodet, X. (1980) "Time-domain formant-wave-function synthesis," in Spoken Language Generation and Understanding, edited by J.C. Sinon (Reidel, Dordrecht, The Netherlands), pp. 429-441.
Scheffers, M.T.M. (1983) "Sifting vowels: Auditory pitch analysis and sound integration," unpublished doctoral dissertation, (University of Groningen, The Netherlands).
Table I. Parameters of the spectral envelopes of vowels. With the
additive synthesis algorithm used, the level values specified as parameters are
those actually obtained in the synthesized signal.
| Formant frequency (Hz) | Bandwidth (Hz) | Level (dB re F1) | |
|---|---|---|---|
| vowel /a/ | 600 | 78 | 0 |
| 1050 | 88 | -6 | |
| 2400 | 123 | -12 | |
| 2700 | 128 | -11 | |
| 3100 | 138 | -24 | |
| vowel /i/ | 238 | 73 | 0 |
| 1741 | 107 | -20 | |
| 2450 | 123 | -16 | |
| 2900 | 132 | -20 | |
| 4000 | 150 | -32 | |
| vowel /o/ | 360 | 51 | 0 |
| 750 | 61 | -11 | |
| 2400 | 168 | -29 | |
| 2675 | 183 | -26 | |
| 2950 | 198 | -35 |
Table II. Results of separate three-way analyses of variance for each
target vowel at vibrato widths of 3% and 6%. In each cell is shown the
probability that the null hypothesis was true.
| /a/ | /i/ | /o/ | |||||
|---|---|---|---|---|---|---|---|
| Source | d.f. | 3% | 6% | 3% | 6% | 3% | 6% |
| Tracing | (1,708) | n.s | .001 | n.s.* | 0.27 | n.s | n.s.* |
| Permutation | (5,708) | <.001 | <.001 | <.001 | <.001 | n.s. | <.001 |
| Modulation | (5,708) | .003 | <.001 | n.s. | <.001 | n.s. | <.001 |
*These effects approached significance (p < .06).
Table III. Results of post hoc orthogonal contrasts for each target
vowel at vibrato widths of 3% and 6%: a) among conditions within which the
target vowel is modulated, and b) among various grouped conditions. In each
cell is shown the probability that the null hypothesis was true for F(1,708).
Vmod indicates the condition where only the target vowel is
modulated (Amod, Imod, or Omod,
accordingly). Unmod indicates a grouping of all conditions in
which the target vowel is not modulated. Allmod indicates a
grouping of Cohmod and Sepmod.
| Contrast | /a/ | /i/ | /o/ | ||||
|---|---|---|---|---|---|---|---|
| 3% | 6% | 3% | 6% | 3% | 6% | ||
| a) | Vmod vs Cohmod | .007 | <.001 | n.s. | .013 | n.s. | <.001 |
| Vmod vs Sepmod | n.s. | .015 | n.s. | <.001 | n.s. | .010 | |
| Cohmod vs Sepmod | .040 | n.s. | n.s. | n.s. | n.s. | n.s. | |
| b) | Unmod vs Vmod | .004 | <.001 | n.s. | <.001 | n.s. | <.001 |
| Unmod vs Allmod | n.s. | <.001 | n.s. | <.001 | n.s. | .001 | |
| Vmod vs Allmod | n.s. | <.001 | n.s. | .001 | n.s. | <.001 | |
Table A.I. Results of the concurrent vibrato rate discrimination experiment (mean percent correct responses).
| F0 pair (Hz) | Vibrato rate pair (Hz)
| |
|---|---|---|
| 5.1 / 6.3 | 5.1 / 5.7 | |
| 130.8 / 174.6 | 98 | 94 |
| 174.6 / 233.1 | 97 | 96
|
| 130.8 / 233.1 | 51 | 58
|
____________________________
Server © IRCAM-CGP, 1996-2008 - file updated on .
____________________________
Serveur © IRCAM-CGP, 1996-2008 - document mis à jour le .