Tous droits réservés pour tous pays. All rights reserved.
| Serveur © IRCAM - CENTRE POMPIDOU 1996-2005. Tous droits réservés pour tous pays. All rights reserved. |
Rapport Ircam 6/78, 1978
Copyright © Ircam - Centre Georges-Pompidou 1978
This paper reports the results of work done over the last two years in searching for ways to improve the quality of speech synthesis. The findings were determined by largely informal listening tests with trained musicians.
where
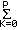 akZ-k
a0=1
akZ-k
a0=1
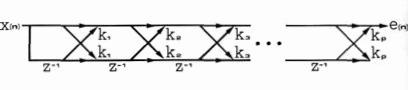
is known as the inverse filter, G is a gain factor, ak are the filter coefficients, and p is the number of poles or predictor coefficients in the model. If H(z) is stable (minimum phase), A(z) can be implemented as a lattice filter (Itakura and Saito) as shown in figure 1. The reflection (or partial correlation) coefficients Km in the lattice are uniquely related to the predictor coefficients. For a stable H(z), we must have
 m p
m p
Figure 1 - Latice form of inverse filter.
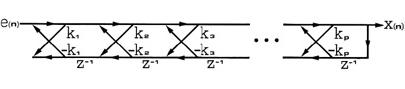
H(z) can also be implemented as a lattice form as shown in figure 2, as
Figure 2 - Latice form of all-pole filter. The filter is unconditionally stable if all the coefficients are of magnitude less than one.
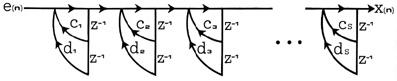
well as a product of first and second order sections by factoring A(z) and combining complex conjugate roots to form second order sections with all real coefficients as shown in figure 3.
Figure 3 - Factorization of all-pole filter into second order sections.
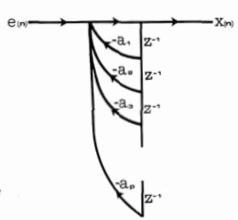
Finally, the filter can be implemented in direct form as shown in figure 4.
Figure 4- Direct form for the realization of an all-pole filter.
We are excluding for the time being models which include both poles and zeros since we have not as yet investigated a satisfactor, method to compute both poles and zeros reliably.
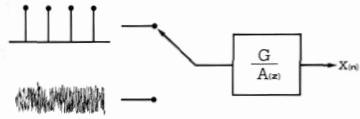
To actually synthesize a speech sound, one must drive this filter with something. This is called the excitation, and it too must be modeled to provide a reasonable representation of the speech excitation. We usually choose the excitation to be either white noise for unvoiced sounds, a wide-band pulse train for voiced sounds, or silence (for silence) as shown in figure 5, although this simplification should be discussed further.
Figure 5 - Schema of the synthesis of speech using as excitation either a pulse train or white noise.
Thus to summarize, if we wish to synthesize speech, the process from analysis to synthesis might be the following:
Readers wishing to know more about the subject of linear prediction of speech should refer to the literature (Markel and Gray 1976, Makhoul 1975).
There are numerous other decisions to be made, such as choosing a method for doing each of these things, choosing the order of the filter, deciding what form the filter should be in, how to interpolate the yarameters between. We will attempt to comment on each of these.
In general, there is no point in directly resynthesizing a piece of speech or singing. One could just use directly the original segment. The only point is to be able to modify the speech in ways that would be difficult or impossible for the speaker to do. These include modifications of the driving function, such as changing the pitch or using more complex signals, changing the timing of the speech, or actually altering the spectral composition. Thus we will concentrate here not only on methods that preserve the speech quality in an unmodified reconstruction, but also that are less sensitive to modification, that can preserve the quality over a wide range of modifications.
Next is the voiced-unvoiced-silence decision. This seems to be the most difficult part to automate. So difficult, in fact, that we have taken to using a graphics program to allow the composer to go through and mark the segments himself. We use a decision theoretic procedure for the initial labeling (Atal and Rabiner 1976, Rabiner and Sambur 1977). We then synthesize an unmodified trial replica of the original sound. Using graphics, 150 millisecond windows of both the original and the replica are presented. The voiced-unvoiced-silence decision as determined by the computer is listed below the images. When the differences between the original and the replica seem to indicate an error in the decision, it is easily corrected by hand. It takes about 15 miniutes to go through a 12-second segment of speech this way, which represents, for instance, about one stanza of a poem (between 35 and 40 words).
One can decrease the effect of this phenomenon in several ways. First, by use of an all- pass filter, one may distort the phase of the speech to largely eliminate the prominance of the glottal pulse (Rabiner, et al, 1977). One can also use a larger analysis window such that more main pulses are incorporated, such that the omission or inclusion on one pulse does not perturb the filter so strongly. Both of these remedies have the effect of blurring what are often quite sharp boundaries between voiced and unvoiced sounds. The problem is that if the analysis window overlaps significantly an unvoiced region, the extreme bandwidth of the unvoiced signals contributes to a filter that passes a great deal of high frequencies. If this filter is then used to synthesize a voiced sound, a strong buzzy quality is heard. The overall effect was that just around fricatives, the voice before and after had a strongly buzzy quality.
Another problem with using analysis windows larger than a single period is that the filter begins to pick up the fine structure of the spectrum. The fine structure is composed of those features that contribute to the excitation, notably the pitch of the sound. At the high order required for high-quality sound on wide-bandwidth original signal (we are using 55th order filters for a deep male voice with a sampling rate of 25600 Hertz), the filter seems to capture some of the pitch of the original signal from overlapping several periods at once. The result is that even though reasonable unmodified synthesis can be obtained, the sound deteriorates greatly when the pitch is changed. This, then, is a case where the unique musical application of modification implies a more substantial change from speech communication techniques.
The solution that we adopted was the use of pitch synchronous analysis, where the analysis window is set to encompass exactly one period, and it is stepped in time by exactly one period. This prevents any fine structure representing the pitch from being incorporated into the filter itself. It also provides that in the case of the borders between voiced and unvoiced regions, no more than one period will overlap the border itself. The step size and window width is not so critical in the unvoiced portions, so we simply invent a fictitious pitch by interpolating between the known frequencies nearest the unvoiced region. There does remain a slow variation in the filters presumably caused by inaccuracies in the pitch detection process. This can be somewhat lessened by the all-pass filter approach (Rabiner, et al, 1977), but it does not seem to be terribly annoying in musical contexts.
Note that the adoption of pitch-synchronous analysis has implications for the type of prediction used. The most popular method is the autocorrelation method, but its necessary windowing is not appropriate for pitch-synchronous analysis. Some kind of covariance or latice method is then required. What we have chosen is Burg's method (Burg 1967) because it does correpond to the minimization of an error criterion, the filter is unconditionally stable, and there exists a relatively efficient computational technique (Makhoul 1977). We have tried straight covariance methods with the result that the instabilities of the filters are inherent at high orders in certain circumstances and somewhat difficult to cure. One can always factor the polynomial and replace the ailing root by its inverse, then reassemble the filter, but besides being expensive, there is another reason to be discussed subsequently that is even more compelling.
There are also a number of recursive estimation techniques (Morgan and Craig 1976, Morf 1974, Morf, et al, 1977) which allow one to compute the coefficients from the previous coefficients and the new signal points. This has the advantage that no division of the signal into discrete windows is necessary. In fact, no division is possible. The problem is, again, that if the "memory" of the recursive calculation is short enough to track the rapid changes, such as from an unvoiced region to a voiced region, then it also tracks the variation of spectrum throughout a single period of the speech sound. The short-term spectrum changes greatly as the glottis opens and closes. If the memory of the calculation is long enough to smooth out the intra-period variations, then it also tends to mix the spectra of the adjacent regions.
The problem with the single pulse is that it is not a band-limited signal. In places where the pitch is changing rapidly, this produces a roughness in the sound that is quite annoying. For this reason, it is generally preferable to use a band-limited pulse of some sort Wynam and Steiglitz 1970). One can further improve the sound by scrambling somewhat the phases of the components of the band-limited pulse to prevent the highly "peaky" appearance, but this is frosting on the cake that is not clearly perceived by most listeners. It is audible, but it is not the dramatic transformation from harsh to melifluous that one might hope. We synthesize the pulse by an inverse fast Fourier transform. This allows us to set the phases of each component independently. We found that a slight deviation from zero phase was desirable and easily accomplished by adding a random number into the phase corresponding to -.5 to +.5 (radians) seemed sufficient to "round off" the peak. Since using the FFT is a somewhat expensive way to compute the excitation, we computed it only when the frequency changed enough that a harmonic had to be ommitted or added. The synthesized driving signal was kept in a table and sampled at the appropriate rate to generate the actual excitation. This provided another benefit that we will discuss presently. Also, since recomputing the driving function using semi-random phases can give discontinuities when changing from one function to a new one, we used a raised cosine to round the ends of the driving function to zero. If a DC term is present, this is known to leave the spectrum unchanged, except for the highest harmonics, so we are assured that the driving spectrum is exactly flat up to near the maximum harmonic. The raised cosine was applied just at the beginning 10 percent and ending 10 percent of the function.
The production of the noise for the unvoiced regions does not seem to be highly critical. We are using Gaussian noise (Knuth 1969).
One might ask why we attempt to synthesize the driving function. Why not use the residual of the original signal directly? This indeed has the advantage that there is no pitch detection involved and no voiced-unvoiced-silence decision at all. The problem is that then for musical purposes, one must be able to modify the residual itself. There exist methods for doing this using the phase vocoder as a modification tool ( Moorer 1976, Portnoff 1976). There is even a recent study about making the phase vocoder more resistant to degradation from modification (Allen 1977).
The problem is that to produce the residual, it is often necessary to amplify certain parts of the spectrum that might have been very weak in the original. The very definition of "whitening" the signal is to bring all parts of the spectrum up to a uniform level. There are inevitable weak parts of the spectrum-nasal zeros or some such. If there is precious little energy at a certain band of frequencies, then the whitening process will simply amplify whatever noise was present in the recording process. If this resulting noise then falls under a strong resonance when the prediction filter is then applied, this filter then just amplifies that noise. The perceptual effect is that the signal looses its "crispness" and becomes "fuzzy", and sometimes even downright noisy.
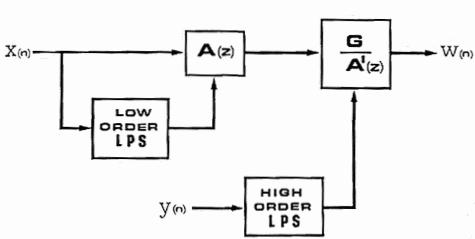
One can do this also with a low-order linear predictor as shown in figure 6. The error signal of a 4th to 6th order linear prediction process is usually sufficiently whitened to improve the intelligibility greatly, but at the expense of the clarity of the original musical source. In fact, one can choose from a continuum of sounds between the original musical source and the speech sound. Depending on the compositional goals, one might choose something more instrument-like and scarcely intelligible, progressing through stages of increasing intelligibility, or whatever.
Figure 6 - Diagram of cross synthesis. The source signal, X(n), might be a musical instrument. Its spectrum is whitened by a low-order optimum inverse filter, then filtered by a higth-order all-pole filter representing the spectrum of another signal, Y(n), which is presumably a speech signal of some kind.
One can use any sound as excitation with varying results.For instance, if the source sound has very band limited spectral caracteristics, such as an instrument with a very small number of haromonics like a flute, the whitening process will just amplify whatever noise happens to be present in the recording process, producing an effect somewhat like a "whispering" instrument, where the pitch and articulation of the instrument is clearly audible, but the speech sounds distinctly whispered.
One can also deliberately defeat the pitch synchronicity of the analysis to capture the fine structure of the spectrum. If one then filters a wide band sound, such as the sound of ocean waves, one can as the order increases impose the complete sound of the voice on the source. We can in this manner realize something like the sounds of the sirens on the waves, or the "singing ocean". In general, this sort of effect takes a very high order filter. For example, if the vocal signal were in steady-state, it would require one second-order section for each harmonic of the signal. Thus for a low male voice of 40 to 60 harmonics, an order of 80 to 120 would be required. Indeed, our experiments have shown that as the order approaches 100 (or 50 for female voice), the pitch of the vocal sound becomes more and more apparant.
Using the lattice form for the synthesis filter gives us a convenient way of adjusting the order of the filter continuously. Since with the lattice methods, the first N sections (coefficients) of the filter are optimal for that order, we can just add one section after another to augment the order. Setting coefficients to zero, starting from the highest, still produces an optimal filter of a lower order.
This is not true of the direct form or the factored form. Throwing out one coefficient requires changing all the other coefficients to render the filter optimal again. Indeed, instead of just turning a coefficient on or off in the latice form, we may also turn it up or down. That is to say when we add a new coefficient, we may add it gradually, starting at zero, and slowly advancing to its final value (presumably precomputed). This allows us to "play" the order of the filter, causing the vocal quality to strengthen and fade at will in a continuous manner.
Cross-synthesis between musical instruments and voice seems to make the most sense if the two passages are in some way synchronized. We have done this in two different ways to date: one is to record some speech, poetry, or whatever, performed by a professional speaker to achieve the desired presentation, then using synchronized recording and playing, either through a multi-track tape recorder or through digital recording techniques, have the musician(s) play musical passages exactly synchronized with the vocal sounds. This takes a bit of practice for the musician, in that speech sounds in English are not typically exactly rythmically precise, but can nonetheless be done quite precisely. The other avenue is to record the music first to achieve some musical performance goal, then have the speaker synchronize the speech with the musical performance. Either one of these approaches achieves synchronicity at the expense of naturalness in one or the other of the performances, vocal or musical, but renders the combination much more convincing.
We can envision at least three filter structures: direct form, factored form, and latice form. In factored form, the filter is realized using first and second order sections. The direct form is just a single high-order tapped delay line. The problem with the direct form is that it's numerical properties are somewhat less than ideal and that one cannot necessarily interpolate directly the coefficents. If you interpolate linearly between the coefficients of two stable polynomials, the resulting intermediate polynomials are not necessarily stable. Indeed, if the roots of the polynomials are very similar, the intermediate polynomials will probably be stable, but if the roots are very different, the intermediate polynomials are quite likely to be unstable. Thus the direct form is not suitable for interpolation without further thought.
The factored form can be interpolated directly in a stable manner. In a second-order section representing a complex conjugate pole pair, the stability depends largely on the term of delay two. As long as this term is less than unity, the section will probably be stable, depending on the remaining term. There are two problems remaining, though, in the use of the factored form. The first is that the polynomial must be factored. With 55th order polynomials, this is a non-trivial task. There is no estimation technique known that can produce the linear prediction filter in already factored form. Although factoring polynomials is an established science, it is still quite time-consuming, especially with high order. In addition to that, one must also group the roots such that each section changes only between roots that are very similar. Since there is no natural ordering of the roots, one must invent a way of so grouping them. We have tried techniques of minimizing the Euclidian distance on the Z-plane between pairs of roots, and this seems to give reasonable results, except in certain cases when, for instance, real roots collide and form complex conjugate pairs. There is no telling at any given time how many real roots a polynomial will have, and quite often there are one or two real roots that move around in seemingly random fashion. The factored form does, however, have one strong advantage, which is that it is very clear how to directly modify the spectrum at any given point. Since the roots are already factored, it is quite clear which sections control which parts of the spectrum. Moreover, when the roots are interpolated, they form clear, well-defined patterns that have well-defined effects on the spectrum. Except for the inefficiencies involved in factoring and ordering the roots, the factored form seems ideal.
With the latice form, there is no problem in interpolation. The reflection coefficients can be interpolated directly without fear of instabilities because the condition for stability is simply that each coefficient be of magnitude less than unity. When one interpolates, however, between reflection coefficients of two stable filters, the roots follow very complex paths, thus if the filters are not already very similar, one can only expect that the intermediate filters will be only very loosely related to the original filters.
If one wishes to modify the spectrum, however, one must convert the reflection coefficients into direct form and then factor the polynomial. This can be done without problem with the expendature of sufficient quantities of computer time, but the inverse process, converting the direct form back into reflection coefficients, cannot be done accurately. The only process for doing so is highly numerically unstable ( Markel and Gray), so that for higher orders, it simply cannot be done in reasonable amounts of time. Thus, once factored, the polynomial must stay factored for all time henceforth.
For our own synthesis system, we currently use the latice form because it uses directly the output of the analysis technique and because interpolation can be used easily on the reflection coefficients.
Filter coefficients are, of course, not the only things that must be interpolated. The frequency must also be continuously interpolated for the most smooth sounding results. This is where the advantage of using table lookup for the excitation occurs. With table lookup, one can continuously vary the rate at which the table is scanned. If one uses interpolation on the table itself, the resulting process can be made very smooth indeed. Again, the table must be regenerated each time the frequency changes significantly, but this seems to occur seldom enough to allow the usage of the FFT for generating the excitation function.
Atal (Atal and Hanauer 1971) used a method of normalization of energy such that the energy of the current frame (period) is scaled to correpond exactly to the original energy. Although this sounds like the right thing to do, it has several problems. First is just the way it is calculated. The filter has presumably been run on the previous frame and now has a non-zero "memory". That means that even with zero input this frame, it will emit a certain response that will presumably die away. We seek, then, to scale the excitation for this frame such that the combination of the remaining response from the previous frame and the response for this frame (starting with a fresh filter this frame) will have the correct energy. Since the criterion is energy, a squared value, this reduces to the solution of a quadratic equation for the gain factor. The problem comes when the energy represented by the tail of the filter response from the previous frame already exceeds the desired energy of this frame. In this case, the solution of the quadratic is, of course, complex. What this means is that the model being used is imperfect. Either the filter or the excitation is not an accurate model of the input signal. This is possible since the modeling process, especially for the excitation, is not an exact procedure. There are even instabilities that can result in the computation of the gain. For instance, if the response from the last frame is large, but not quite as large as the desired energy, then a very small value of gain will be computed. That means that in the next frame, there will be very little contribution from the previous frame and the gain factor will be quite large. As the model deteriorates, this oscillation in the gain increases until no solution is possible. The only hope is that this occurs sufficiently rarely as to not be a detriment. Experience, however, seems to indicate the contrary: that this failure in modeling is something that happens even in quite normal speech and must be taken into account. Besides all that, even if you do normalize the energy, the perceived loudness will often be found to change noticably over the course of the utterance. This is especially true during voiced fricatives, although the theoretical explanation for this phenomenon is not clear at this time.
The method of amplitude control that we have chosen is two-fold: for cross-synthesis, we choose a two-pass post- normalization scheme that computes the energies of the original signal and the synthesized signal. The synthesized signal is then multiplied by a piecewise-linear function, the breakpoints of which are the gain factors required to normalize the energy at the points where the energies were computed.
For resynthesis of the vocal sounds, we use an open-loop method of just driving the filter with an excitation that correponds in energy to the energy of the error signal of the inverse filter. This is, of course, only an approximation because the excitation never corresponds to the actual error signal, but in practice it seems to produce the smoothest most naturally varying sounds. Note also that this does not guarantee any correspondance between the energies of the original and the synthetic signals. With the autocorrelation method of linear prediction, the error energy is easily obtained as an automatic result of the filter computation. For other methods, it is generally necessary to actually apply the filter to the original signal to obtain the error energy. As with all other parameters, we interpolate the gain in a continuous piecewise-linear manner throughout the synthesis.
These techniques have been embodied in a series of programs that allow the
composer to specify transformations on the timing, pitch, and other parameters
in terms of piecewise-linear functions that can be defined directly in terms of their breakpoints,
graphically, or implicitly in terms of resulting contours of time, pitch, or
whatever. More work must be done in arranging these in a more convenient
package for smoothly carrying the system through from start to finish without
excessive juggling and hit-or-miss estimation.
ATAL, (B.S.), SCHROEDER, (M.R.), Adaptive Predictive Coding of Speech
Signals, Bell Syst. Tech. J., vol. 49, 1970, ppl973-1986.
ATAL, (B.S.), HANAUER, (S.L.), Speech Analysis and Synthesis by Linear
Prediction of the Speech Wave, J. Acoust. Soc. Amer., vol. 50, pp 637-655,
Feb.1971.
ATAL, (B.S.), RABINER, (L.R., A Pattern Recognition Approach to Voiced-Unvoiced-Silence
Classification with Applications to Speech Recognition, IEEE Trans. Acoust.,
Speech, and Signal Processing, vol. ASSP-24, pp201-211 June 1976.
BURG, (J.P.), Maximum Entropy Spectral Analysis, presented at the 37th
Annual Meeting Soc. Explor. Geophy., Oklahoma city, OK, 1967.
DODGE, (C.), Synthetic Speech Music, Composer's Recordings, Inc., New York,
CRI-SD-348, 1975 (disk).
GOLD, (B.), RABINER, (L.R.), Parallel Processing Techniques for Estimating
Pitch Periods of Speech in the Time Domain, J. Acoust. Soc. Amer., vol 46, no.2,
August 1969, pp442-448.
ITAKURA and SAITO, Digital filtering techniques for speech analysis and
synthesis, presented at the 7th International Congress on Acoustics, Budapest,
1971, Paper 25-C-1.
MAKHOUL, (John), Lattice Methods for Linear Prediction, IEEE Trans. on
Acoustics, Speech, and Signal Processing, vol ASSP-25,no.5, October 1977, pp423-42S.
MAKHOUL (J.), Linear Prediction: A Tutorial Review, Proceedings of the
IEEE, Vol. 63, April 1975, pp561-580.
MARKEL, (J.D.), GRAY, (A.H.), Linear Prediction of Speech, Springer-Verlag,
Berlin Heidelberg, 1976.
McGONEGAL, (C.A.), RABINER (L.R.), ROSENBERG (A.E.), A Subjective
Evaluation of Pitch Detection Methods Using LPC Synthesized Speech, IEEE
Trans. on Acoustics, Speech, and Signal Processing, voL ASSP- 25, no., June 1977, pp221-229
MOORER, (J.A.), The Optimum Comb Method of Pitch Period Analysis of
Continuous Digitized Speech, IEEE Trans. Acoust., Speech, and Signal
Processing, vol. ASSP-22, October 1974, pp330-338.
MOORER, (J.A.), The Synthesis of Complex Audio Spectra by Means of Discrete
Summation Formulas, J. Aud. Eng. Soc., Vol 24 , no.9, November 1976, pp717-727.
MOORER (J.A.), Signa1 Processing Aspects of Computer Music: A Survey, Proc.
of the IEEE, vol 65, no.8, August 1977, pp1108-1137.
MORF, (M.), Fast Algorithms for Multivariable Systems, PhD thesis,
Dept. of Electrical Engineering, Stanford University,
Stanford California, 1974.
MORF, (M.), VIEIRA, (A), LEE (D.T.), KAILATH, (T), Recursive
Multichannel Maximum Entropy Method, Proc. 1977 Joint Automatic
Control Conf., San Francisco, California, 1977.
MORGAN, (D.R.), CRAIG (S.E.), Real- Time Adaptive Linear
Prediction Using the Least Mean Square Gradient Algorithm,
IEEE Trans. on Acoustics, Speech, and Signal Processing, vol ÀSSP-24, no.6, December 1976, pp494-507.
NOLL (A.M.), Cepstrum Pitch Determination, J. Acoust. Soc.
Amer., vol 41, February 1967, pp293-309.
PETERSEN, (T.L.), Vocal Tract Modulation of Instrumental Sounds
by Digital Filtering, presented at the Music Computation Conf.
II, School of Music, Univ. Illinois, Urbana-Champaign, Nov. 7-9, 1975.
PETERSEN, (T.L.), Dynamic Sound Processing, in Proc. 1976
ACM Computer Science Conf. (Anaheim, California), February 10-12, 1976.
PETERSEN (T.L.), Analysis-Synthesis as a Tool for Creating
New Families of Sound, presented at the 54th Conv. Audio Eng.
Soc. (Los Angeles, California), May 4-7, 1976.
PORTNOFF, (M.R.), Implementation of the Digital Phase Vocoder
Using the Fast Fourier Transform, IEEE Trans. on Acoustics,
Speech, and Signal Processing, vol ASSP- 24, no.3, June 1976, pp243-248.
RABINER (L.R.), CHENG, (M.J.), ROSENBERG, (A.E.), McGONEGAL, (C.A.),
A comparative Performance Study of Several Pitch Detection
Algorithms,IEEE Trans. on Acoustics, Speech, and Signal
Processing, vol ASSP-24, no.5, October 1976, pp399-418.
RABINER (L.R.), SAMBUR, (M.R.), Application of an LPC Distance
Measure to the Voiced-Unvoiced-Silence Detection Problem, IEEE
Trans. on Acoustics Speech, and Signal Processing, vol ASSP-25, no.4, August 1977, pp338-343.
RABINER, (L.R.), ATAL, (B.S.), SAMBUR, (M.R.), LPC Prediction
Error-Analysis of Its Variation with the Position of the Analysis Frame, IEEE
Trans. on Acoustics, Speech, and Signal Processing, vol ASSP-25, no.5, October 1977, pp434-442.
ROBINSON, (E.A.), Statistical Communication and Detection, Hafner, New York, 1967.
SONDHI,(M.M.), New Methods of Pitch Extraction, IEEE
Trans. Audio Electroacoust., vol AU-16, June 1968, pp262-266.
STEIGLITZ, (K.), On the Simultaneous Estimation of Poles and
Zeros in Speech Analysis, IEEE Trans. Acoust., Speech and Signal Processing,
vol. ASSP-25, no.3, June 1977, pp229-234.
TRIBOLET, (J.M.), Identification of Linear Discrete Systems with
Applications to Speech Processing, MS Thesis, MIT Department of Electrical
Engineering, January 1974.
ZWICKER, (E.), SCHARF, (B.), A Model of Loudness Summation, Psychol. Rev.,
vol. 1, 1965, pp3-26.
WINHAM, (G.), STEIGLITZ (K), Input Generators for Digital Sound Synthesis,
J. Acoust. Soc. Amer., vol 47, no.2 (part 2), pp665-666, 1970.
____________________________ ____________________________REFERENCES
ALLEN (J.B.), Short Term Spectral Analysis,
Synthesis, and Modification by Discrete Fourier Transform, IEEE Trans. on Acoustics, Speech, and Signal
Processing, vol ASSP-25, no.3, June 1977, pp 235- 238
Server © IRCAM-CGP, 1996-2008 - file updated on .
Serveur © IRCAM-CGP, 1996-2008 - document mis à jour le .